

Introduction
In today’s data-driven world, data teams vary widely in their tooling, infrastructure, and maturity. Some operate as centralized Data Offices, managing enterprise-wide analytics, while others are embedded teams within departments like finance, marketing, or operations, using SQL and BI tools to generate insights.
Some companies have fully integrated Data Lakehouse and AI-driven platforms, while others rely on Excel spreadsheets and PowerPoint reports.
So how do you assess where your data team stands? Understanding the four levels of maturity can help identify gaps, inefficiencies, and the next steps for evolving towards scalable, flexible, and efficient data ecosystems.
🔴 Level 0 – Unstructured Data Management
Data? Oh yeah, we’ve got spreadsheets for that.
At this stage, data processes are completely ad hoc. There is no structured data management, and most tasks are handled manually. Teams don’t have a dedicated data infrastructure, and reporting relies on exporting CSVs, pivot tables, and PowerPoint slides.
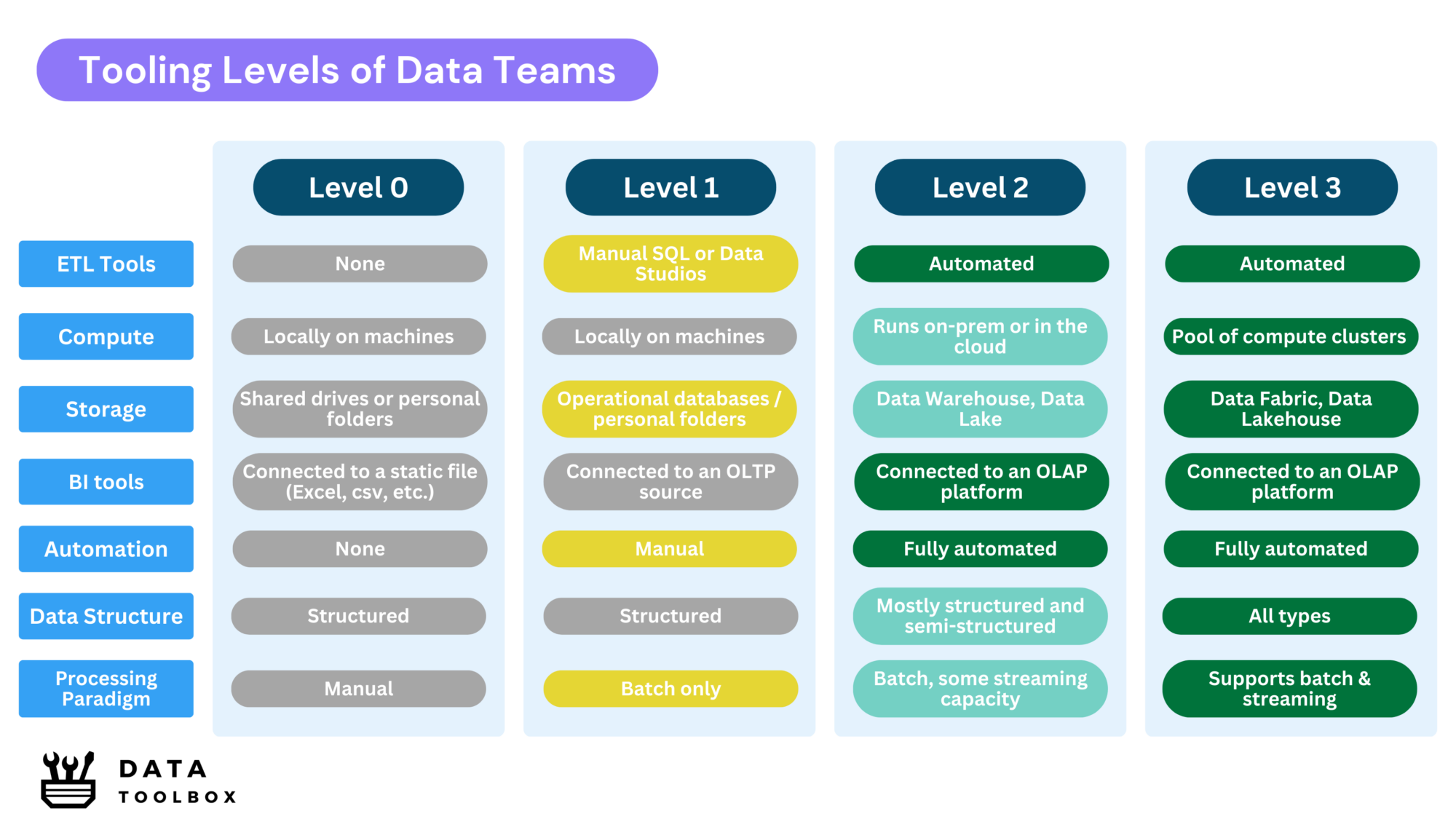
Key Characteristics:
- No ETL tools: data is manually copied and pasted into Excel.
- Compute: Processing takes place on local machines.
- Storage: Scattered files on shared drives or personal folders.
- BI tools: Power BI/Tableau, but connected to Excel instead of databases.
- Automation: None, reports are updated manually.
Challenges:
- No scalability: Data is limited to what fits in Excel.
- Error-prone: Manual data handling leads to inconsistencies.
- No real-time insights: Data is outdated before it’s even analyzed.
🟡 Level 1 – Structured Data Interaction
We know how to query using SQL and use some data tools, but our stack is still fragmented.
At this level, teams start querying structured databases but lack centralization. BI and analytics depend on local SQL queries, Excel workbooks, and isolated data sources. While some automation exists, data processes remain largely manual and department-specific.
Key Characteristics:
- ETL: Manual SQL scripts, low-code tools or data studios like Alteryx, Dataiku or PowerApp.
- Compute: Processing mainly takes place on local machines, such as Excel or Jupyter Notebooks.
- Storage: There is no dedicated analytical storage, data resides in operational databases (OLTP) such as RDBMSs like PostgreSQL, MySQL, and SQL Server, or in document databases, and even in personal files.
- BI tools: Power BI/Tableau, often connected directly to source databases.
- Automation: Basic, but not fully integrated into pipelines.
Challenges:
- Data silos: Teams create their own queries, leading to redundancy.
- Lack of standardization: Each team manages its own processes, making collaboration difficult..
- Scalability issues: Queries on live production databases can cause performance bottlenecks. Never run a SELECT * on a production database ! (see article Analytical vs Transactional)
🟢 Level 2 – Centralized Data Warehousing
We have a data warehouse and structured analytics, but we still work in batch mode.
At this level, data is centralized into a managed warehouse, and analytics workflows are more systematic. The team maintains structured data pipelines, reducing reliance on raw source systems. However, processing is still batch-based, oriented on structured and semi-structured data, where real-time analytics is not yet implemented.
Key Characteristics:
- ETL & Orchestration: Automated with tools like Airbyte, dbt, Airflow, Fivetran.
- Compute: Processing runs on-prem or in the cloud (JupyterHub, AWS, GCP, Azure).
- Storage: Dedicated analytical storage like Data Warehouse (Snowflake, BigQuery, Redshift, etc.).
- BI tools: Power BI, Tableau, but now connected to a Data platform instead of raw sources.
- Automation: ETL workflows are fully automated, but data is processed in batch mode only.
- Processing capacity: Batch-based, structured & semi-structured data.
Challenges:
- No real-time event processing, everything is scheduled in batches.
- Compute limitations, large-scale analytics are constrained by warehouse limitations.
🔵 Level 3 – Advanced Data Architectures
We process both batch and real-time data. Our infrastructure is scalable and AI-ready.
Here, the data team moves beyond structured warehouses and integrates real-time streaming, unstructured data handling, and scalable compute power. Machine learning pipelines are introduced, and data processing is hybrid—both batch and event-driven.
Key Characteristics:
- ETL & Orchestration: Automated with tools like Airflow, dbt, Kafka, Flink.
- Compute: On-demand compute clusters (e.g. Spark pools).
- Storage: Dedicated analytical storage like Data Lakehouse (Delta Lake, Iceberg, Hudi) for structured & unstructured data.
- Analytics: BI tools + ML models in real-time.
- Automation: Fully automated, event-driven pipelines, with real-time data streaming and machine learning model retraining.
- Processing capacity: Supports batch & streaming (Lambda/Kappa architectures).
To be aware of:
- Higher complexity, requires cross-functional data engineering expertise.
- Data governance must be stronger to ensure data quality, regulatory compliance, and trusted decision-making across the organization.
Key Takeaways
This weapon is your life ⚔️.
Yoda
Understanding where your data team stands is crucial for scaling efficiently and adopting the right tools at the right time.
👉 If tooling maturity shows you how the game is prepared, this next article is about the cards and the players. Curious to see the deck? Roles in the Data/AI World: Poker Cards 🎴