

Disclaimer
This article is part of a series, we highly recommend reading the following articles:
- Analytical vs Transactional: Why You Can’t Mix Oil and Water
- The Foundation of a Scalable Data Architecture : Data Storage
These will provide the necessary context to fully understand the concepts we discuss here.
Introduction
In the previous article, we explored the core components that enable and power the analytics world. Let’s start with a quick one-liner recap of each:
- Databases: Storage systems optimized for storing and managing real-time transactional and/or operational data.
- Operational Data Store: A consolidated, near-real-time repository that integrates operational data from multiple sources.
- Master Data Management: A system for maintaining, and governing a single, consistent, and authoritative source of key business data.
- Data Warehouse: Centralized repository designed for structured and historical data.
- Data Mart: Smaller, subject-specific slices of a DWH.
- Data Lake: Scalable storage for raw, unstructured / semi-structured data.
Today, we’ll take a step back and look at the big picture: how these components work together to form a unified data architecture. We’ll give you an overview of the main architectures currently found in the today landscape 🏞️!
Types of Data Architectures
Before we get into the core of it, here’s a quick visual to show the five key architectures that drive the world of analytics today, so you’ll know exactly what we’re talking about 🧭:

Traditional Data Warehousing
Traditional data warehousing follows a structured, schema-on-write approach. Data is ingested through ETL pipelines into a centralized data warehouse, often complemented by data marts. This architecture ensures a Single Version of Truth (SVOT) by consolidating, transforming, and standardizing data before it’s used.
Why did it emerge ? This was the first architecture (in the 90s) built specifically to decouple analytics from operational systems. Instead of querying production databases directly (which implied risks to performance and data integrity) organizations could now rely on a dedicated analytical environment designed for consolidating different sources, reporting and decision-making.
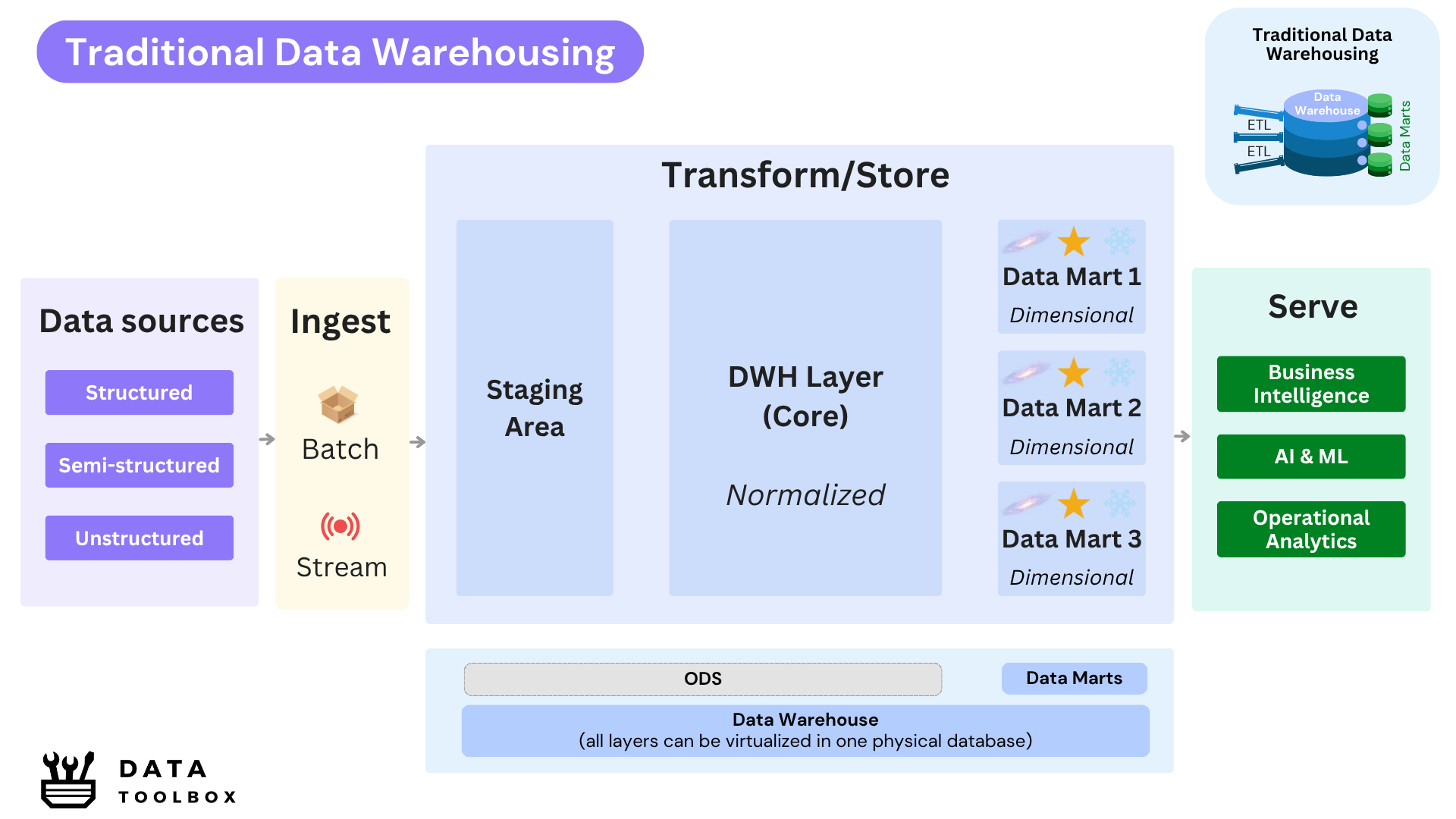
Key Characteristics
- Optimized for structured data using relational databases and supporting historical data analysis.
- Business-focused architecture, with dedicated ETL jobs running to ensure data freshness.
- Ensures data consistency and governance through well-defined schemas.
- Typically follows a layered architecture (see the deep dive) :
- 1️⃣ Staging layer: where structured raw data lands here after extraction, often with minimal transformation.
- 2️⃣ DWH layer (or core): where structured data is cleansed, standardized, and modelized into a normalized model aligned with business domains.
- 3️⃣ Data Mart layer (or presentation): where structured data is reshaped into denormalized views tailored for consumption by reporting tools or dashboards.
Challenges
- High complexity due to rigid data models.
- Streaming is possible in the newest versions, but historically data warehouses have been batch-oriented, leading to higher data latency due to processing cycles, often running only once per day.
- Limited support for semi-structured data (in newer DWH versions) and no support for unstructured data: How can you do AI when you cannot natively store or process media files, documents, or other unstructured content?
And in real-life ?
Imagine a large public sector agency or a multinational insurer operating legacy applications across multiple departments: each with its own CRM, claims, or financial system.
To support enterprise-wide reporting and regulatory compliance, data is extracted daily from these heterogeneous operational systems, sometimes even semi-structured logs or XML exports. It's staged, transformed, and loaded into a centralized, normalized data warehouse, defining shared entities like Customer, Policy, Claim, or Transaction.
From this warehouse, data marts are built for each function—finance, compliance, actuarial—offering curated access to the data they need without exposing the raw sources. The design ensures auditability, traceability, and consistency, aligned with strict governance policies.Legacy but foundational
Traditional data warehouses, built around a central repository and complemented by multiple data marts, are often regarded today as legacy systems. Yet they laid the groundwork for the data architectures we rely on today. Originally deployed on-premises, they have since evolved into fully managed cloud services, while still upholding the core principles of data consolidation, standardization, and governance.
Curious about the how, why, and what’s under the hood? Dive into the full technical breakdown here 👉 Architectural Deep Dive: Traditional Data Warehousing.
Hybrid Data Warehousing
Hybrid Data Warehousing blends the best of two worlds: the structure and governance of traditional data warehouses with the flexibility and scale of data lakes. Instead of choosing between a rigid schema-on-write DWH and a freeform schema-on-read Data Lake, Hybrid Data Warehousing allows organizations to use both.
In this architecture, data flows through a layered pipeline that can land in a Data Lake and/or a Data Warehouse, depending on business needs. It enables organizations to serve both business analysts using SQL tools and data scientists using Python 🐍 (or other languages) to leverage raw/semi-structured datasets for advanced use cases like ML/Gen AI.
Why did it emerge ? When Data Lakes first emerged, many predicted the death 💀 of Data Warehouses. The promise was simple: we can now ingest all types of data cheaply and flexibly. But the reality hit quickly. The “put everything in Data Lake” mindset didn’t work. Without proper metadata, governance, or schema enforcement, many Data Lakes became unmanageable swamps 🐸, making BI nearly impossible. Meanwhile, Data Warehouses struggled to handle modern data challenges like real-time streams and semi-structured formats. That’s where Hybrid Data Warehousing stepped in 🚀, trying to offer the best of both worlds.
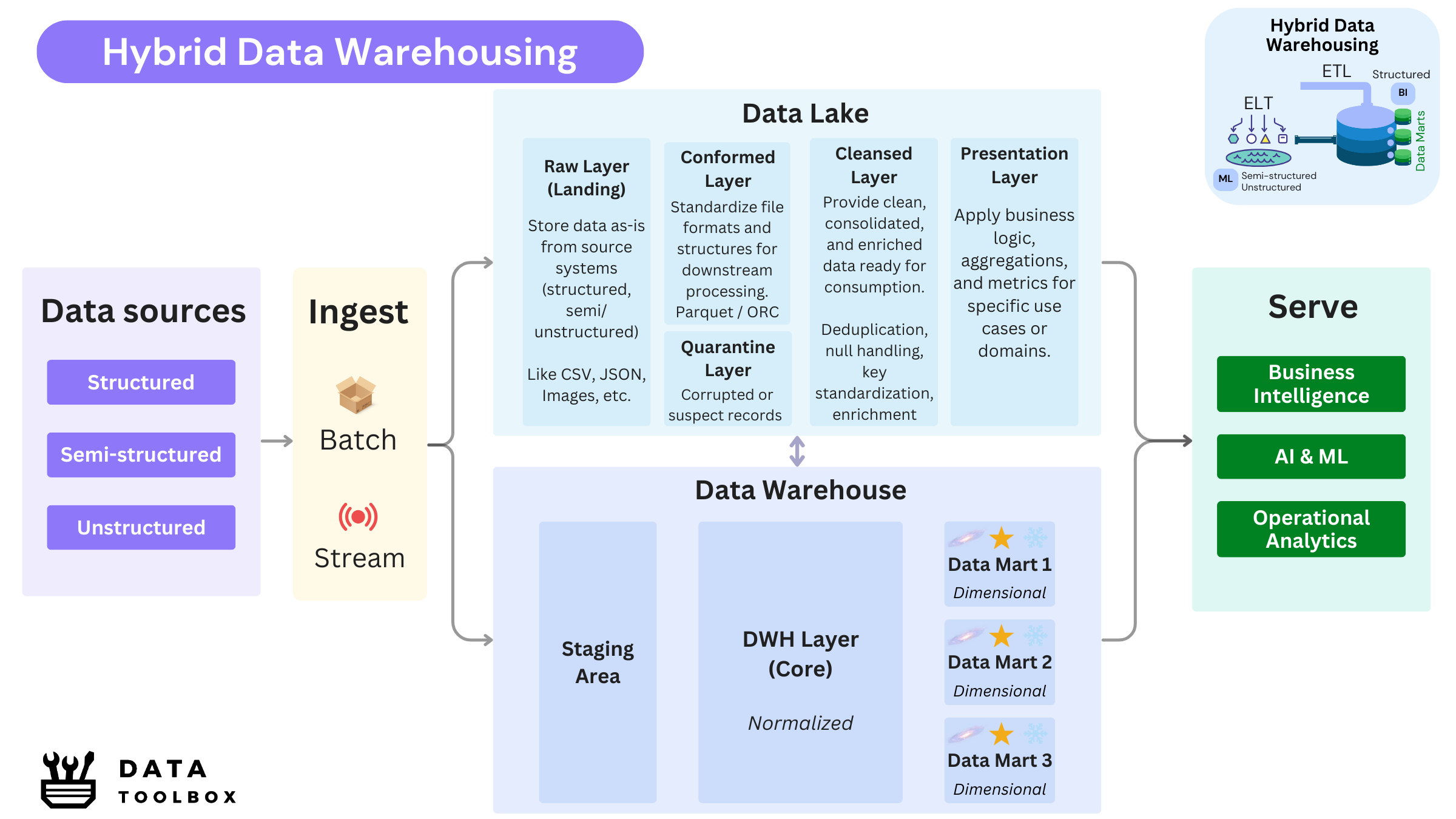
Key Characteristics
- Coexistence of two architectural paradigms: A centralized Data Warehouse (and its associated data marts) operates alongside a Data Lake.
- Dual modeling approaches: Combines schema-on-write (for structured, governed data in the DWH) with schema-on-read (for raw, exploratory data in the DL).
- Versatile ingestion strategies: Supports both ETL pipelines feeding the warehouse and ELT workflows feeding the lake.
- Diverse processing capabilities: Enables SQL-based querying for business users, while leveraging big data tools (e.g., Spark, Hive) for large-scale and semi-structured data processing.
Challenges
- Data duplication ❌: A critical
Clienttable from the CRM is loaded into the Data Warehouse for BI via ELT. Meanwhile, the same table is exported to the Data Lake as a Parquet file for ML use. This results in duplicate data, stored in different formats, with inconsistent metadata, across separate systems. - Higher cost and complexity: You’re maintaining two architectures, requiring more tools, storage, and integration overhead.
- Data governance becomes tricky: Synchronizing access control, lineage, and metadata between the lake and warehouse environments requires tight coordination between data engineers, analysts, and governance teams. This is rarely the case…
And in real-life ?
We will take the example of a major retailer. They deal with high-volume, structured data such as point-of-sale transactions, inventory levels, financial and supplier orders. But they also collect unstructured or semi-structured data like website clickstreams, IoT sensor logs from shelves, and customer reviews.
In a Hybrid DWH setup, the retailer can load structured data like sales and inventory into the Data Warehouse for dashboards and reporting, while also storing it in the Data Lake as raw backups or for advanced forecasting models. Unstructured data, such as customer reviews, are kept in the lake to support natural language processing and behavioral analytics.Looking to explore the architectural deep dive, evolution, and core principles in depth? We’ve got you covered 👉 Architectural Deep Dive: Hybrid Data Warehousing.
Data Lakehouse
Data Lakehouse architecture combines the scalability and flexibility of a Data Lake with the reliability, structure, and performance of a Data Warehouse, all within a single platform. It supports direct analytics on open storage formats like Parquet or ORC, while adding table formats such as Delta, Iceberg, or Hudi to enable transactions, schema enforcement, and metadata management.
It serves both BI analysts and AI/ML practitioners without duplicating data or managing separate pipelines, unlike Hybrid architectures that rely on both a Data Lake and a Data Warehouse.

Key Characteristics
- Built on open file formats like Delta, Hudi, and Iceberg, enabling transactional updates, schema enforcement, and metadata management.
- Enables record-level operations like insert, update, and delete directly in the lake.
- Supports time travel for auditability and historical analysis.
- Optimized for both BI and data science use cases.
- Typically follows a Medaillon architecture:
- 🟤 Bronze: Ingests raw data from diverse sources. Structured and semi-structured data are usually stored in formats such as Parquet or Delta, while unstructured data remains in its original form.
- ⚪ Silver: Processes structured and semi-structured data to apply cleaning and normalization. It improves consistency and schema alignment, stored typically in Delta format for reliability and time travel.
- 🟡 Gold: Contains denormalized domain-specific (or data products) datasets, designed for direct consumption by BI tools, APIs, or ML models.
Challenges
- Relational Layer Is Not Native: BI teams used to relational databases (with stored procedures, views, etc.) face a steep transition to Spark SQL or file-based logic like Parquet or Delta.
- Performance Gaps: While improving rapidly, Lakehouses can still lag behind MPP warehouses in advanced query planning, indexing, and fine-grained access control. They can be more slower today, but they are quickly catching up 🏃 !
And in real-life ?
Think of a fintech company handling transactions, product usage logs, and customer interactions. With a Lakehouse, they can store everything in the same environment and use SQL for dashboards, Spark for ML pipelines, and time travel for historical reviews—all from a single data source.
They stay compliant by deleting data at the record level when required, without rebuilding entire datasets. And they avoid the complexity and cost of maintaining two platforms.Want to know how Data Lakehouse works? Check this 👉 Architectural Deep Dive: Data Lakehouse.
Data Fabric
Data Fabric isn’t a storage architecture like the previous ones, but rather a logical architecture built on top of existing data platforms. Its primary goal is to provide a unified layer for data access and governance across all sources, regardless of their format, technology, or physical location.
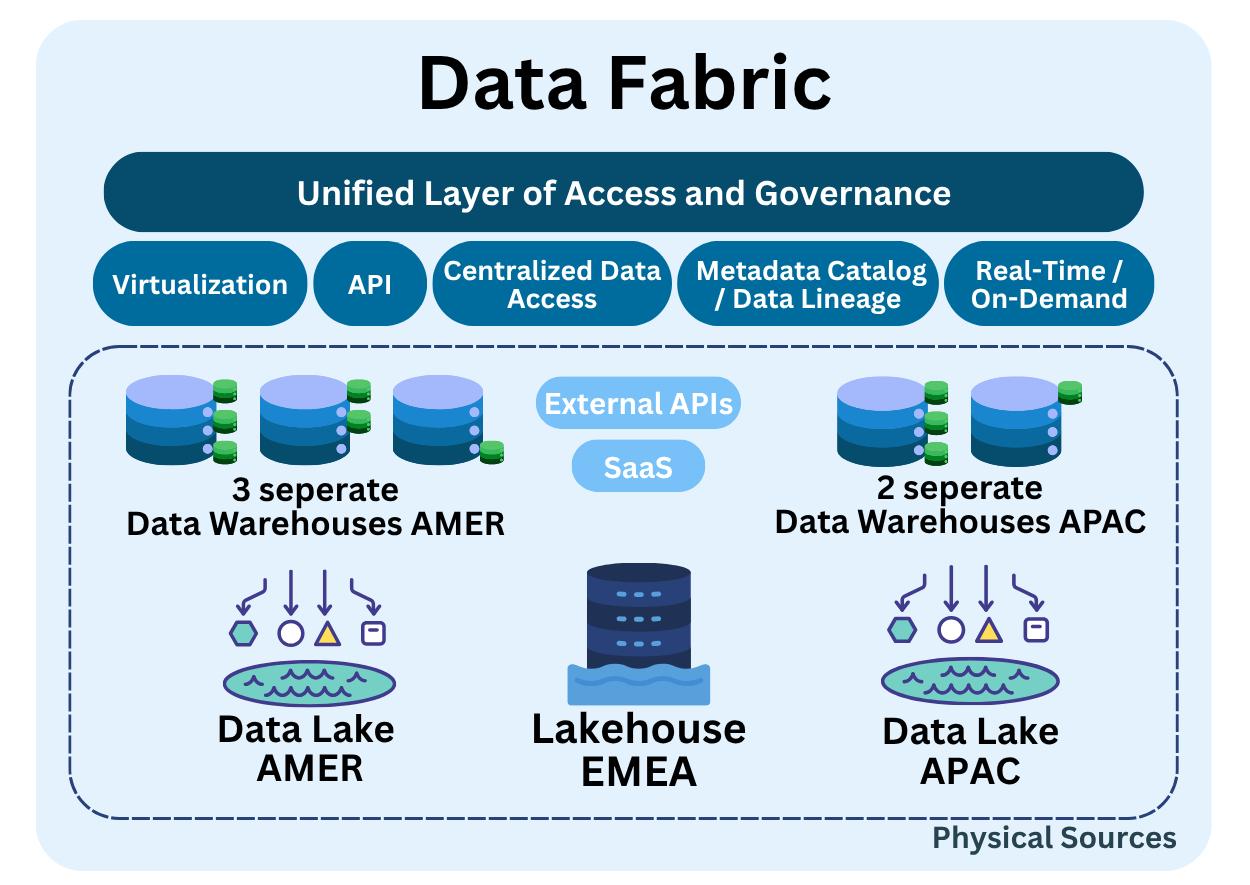
Key Characteristics
- Combines multiple DWH, DL, and Lakehouse into a managed ecosystem.
- Unified data access through virtualization, APIs, and centralized data access.
- Integrated governance including metadata catalog and data lineage.
- Real-time or on-demand processing capabilities for operational analytics.
Challenges
Let’s be clear: Data Fabric doesn’t eliminate complexity, it reorganizes it! It’s often adopted when you can’t centralize storage due to regulatory, geographical, or organizational constraints, like in multi-tenant or multi-region setups.
It acts as a modern Band-Aid 🩹, allowing distributed systems converge into a governed framework. But it comes with trade-offs: higher integration cost, metadata dependency, and a steep setup curve ノ.
And in real-life ?
Imagine a multinational bank with strict regional regulations. European customer data must remain in EU data centers, while U.S. data is stored in different clouds. A global risk analyst wants to calculate exposure across portfolios.
The bank will use a Data Fabric to unify access across all regions without physically moving sensitive data.Want to know how Data Fabric works ? Check this 👉 Architectural Deep Dive: Data Fabric.
Data Mesh
Data Mesh is a decentralized data architecture approach that shifts ownership to business domains, breaking away from centralized IT control. It is not a physical architecture nor a virtual integration layer, but an organizational model that redefines how teams work with data.
Each domain is responsible for its own data products, built with quality, documentation, and governance in mind. It promotes autonomy, cross-functional collaboration, and scalable data delivery
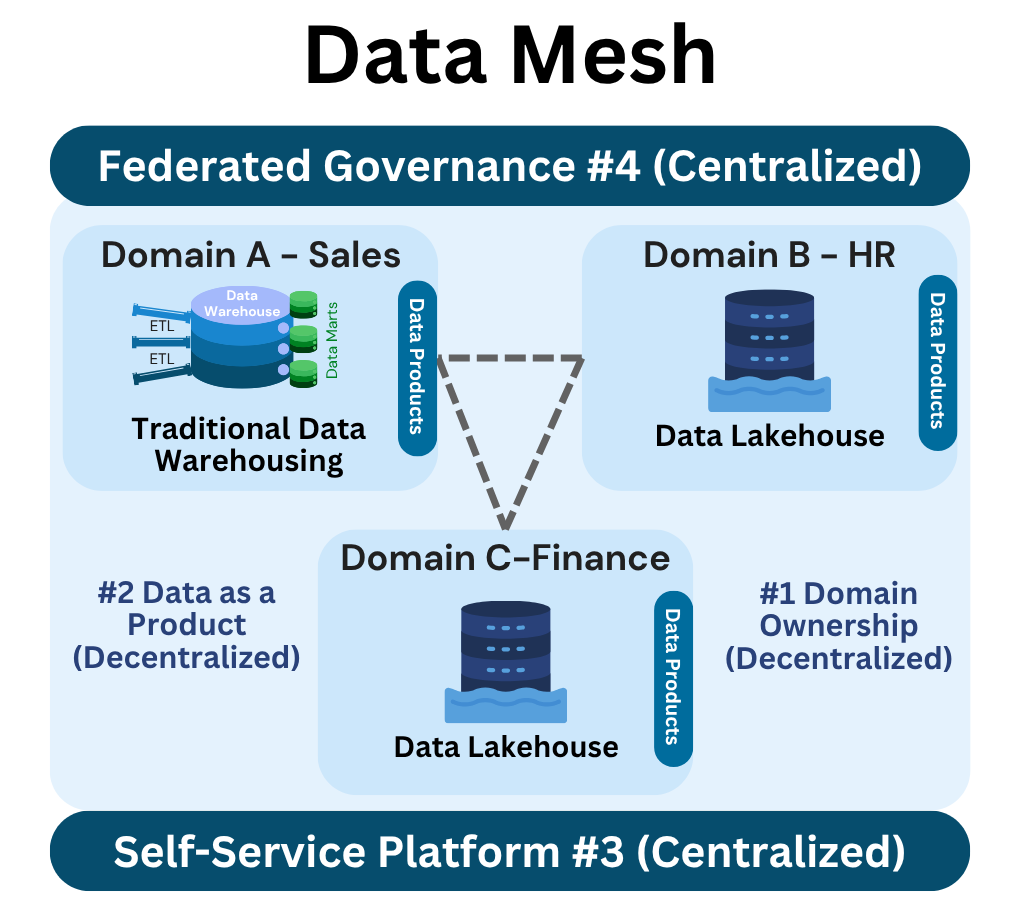
Key Characteristics
- Domain Ownership: Data is owned and managed by domain teams, who are closest to the business context and responsible for the quality and availability of their data.
- Data as a Product: All data outputs, including datasets, dashboards, machine learning models and APIs, are treated as products. Each has clear ownership, proper documentation, defined quality SLAs, and a strong focus on user needs.
- Self-Service Platform: A central team provides reusable tools and infrastructure such as pipeline templates, CI/CD, monitoring and data‑quality controls.
- Federated Governance: Enterprise policies covering security, privacy and metadata are defined centrally, yet enforced locally by every domain.
Challenges
- Platform fragmentation: In theory, each domain can choose its own tech stack (e.g., Databricks, Cloudera, GCP), but in practice, this leads to operational complexity, and exponential costs… 💸
- Interoperability: Sharing data products across heterogeneous stacks introduces friction (authentification, access control or lineage tracking).
- Governance at scale: Maintaining consistency across decentralized teams requires strong policies, metadata, and automation.
- Cultural shift: Domains must adopt a product mindset, take ownership of data quality, and manage infrastructure lifecycles (which is rarely the case).
Interested in exploring the real-world challenges of Data Mesh (and my personnal view 🤫) ? Check this 👉 Architectural Deep Dive: Data Mesh.
Data Platforms, Factories, and Studios
In the data ecosystem, three key components often come up: data platforms, data factories, and data studios.
- Data platforms (e.g. Databricks, Snowflake, BigQuery, Fabric) provide the IT infrastructure to implement and run architectures like warehouses, lakehouses, or meshes. Without them, architectures remain theoretical.
- Data factories: the term is sometimes used as a buzzword to describe a data platform or even a data team (“we produce data products like a factory produces goods“). Other times, it refers more concretely to software that manages data movement and transformation (e.g. Azure Data Factory).
- Data studios sit on top of the data platform. They let users explore, visualise, and share insights through dashboards and reports (e.g. Power BI, Tableau, Looker, Qlik).
Summary
To conclude, let’s take a quick historical look at how data architectures have evolved 📈.
In the 1990s and 2000s, OLAP systems and Data Warehouses marked the first big leap, enabling large-scale analytics through indexing, pre-aggregation, and later columnar storage. By the 2010s, the surge of internet-driven data challenged these systems, giving rise to Big Data technologies and Data Lakes that could finally handle semi-structured and unstructured formats at scale.
The late 2010s introduced a more pragmatic approach: hybrid models that bridged the gap between lakes and warehouses, balancing raw data accessibility for AI/ML with optimized analytics for structured data. This momentum led to the Lakehouse architectures of the 2020s, which unify the flexibility of lakes with the reliability and performance of warehouses.
But once this whole ecosystem was in place, the real challenge became governance and unified access. This is where the paradigm of Data Fabric came in, providing a technological answer, while Data Mesh emerged as the organizational counterpart.
👉 If you want to understand how these architectures act as enablers for creating Data & AI products, click here.