

In our global overview article, we introduced Data Mesh as a decentralized architectural model that shifts data ownership to business domains. Now it’s time to take a closer look at this disruptive and often misunderstood approach (where each person seems to have their own definition 🙃).
While architectures like data warehouses, lakehouses, or fabric are focused on physical or logical layers for managing data, data mesh is primarily about organizational design.
The purpose of this model is to answer the same recurring questions we hear in large companies: Who owns the data? How it is produced and consumed? What are the responsibilities of each team?
These questions might seem simple when you’re dealing with small teams working closely together. But once you’re in an enterprise dealing with huge data volume, with multiple IT and data teams across countries or business units, the answer becomes less and less obvious 😕.
Quick Recap ↻
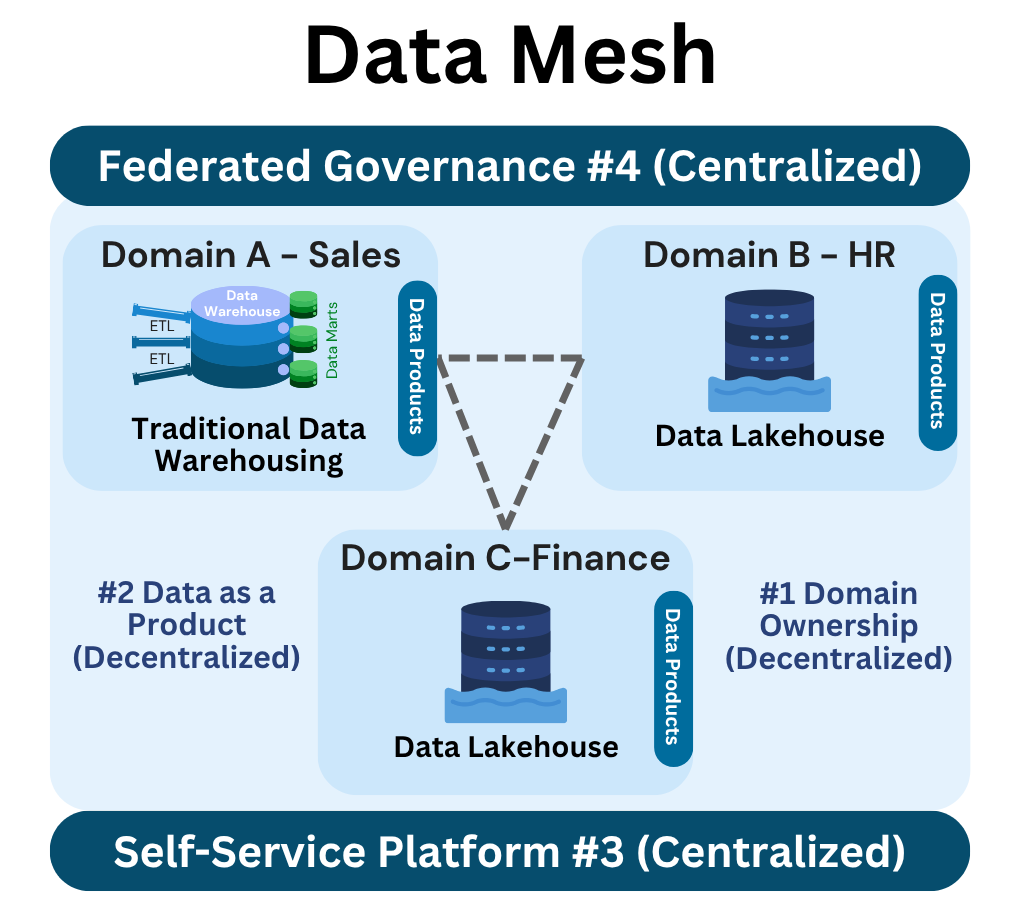
The term Data Mesh was popularised by Zhamak Dehghani in 2019, and her 2022 book Data Mesh, Delivering Data‑Driven Value at Scale is regarded as the foundational reference for the discipline. To be clear, Data Mesh is not a product, nor a specific tool. It’s an organizational model based on four core principles:
- Domain Ownership: Data is owned and managed by domain teams, who are closest to the business context and responsible for the quality and availability of their data.
- Data as a Product: All data outputs, including datasets, dashboards, machine learning models and APIs, are treated as products. Each has clear ownership, proper documentation, defined quality SLAs, and a strong focus on user needs.
- Self-Service Platform: A central team provides reusable tools and infrastructure such as pipeline templates, CI/CD, monitoring and data‑quality controls.
- Federated Governance: Enterprise policies covering security, privacy and metadata are defined centrally, yet enforced locally by every domain.
The philosophy is to move away from a centralized IT team that can’t keep up with business demands, and enable each team to manage its own data responsibly.
Data Mesh Types
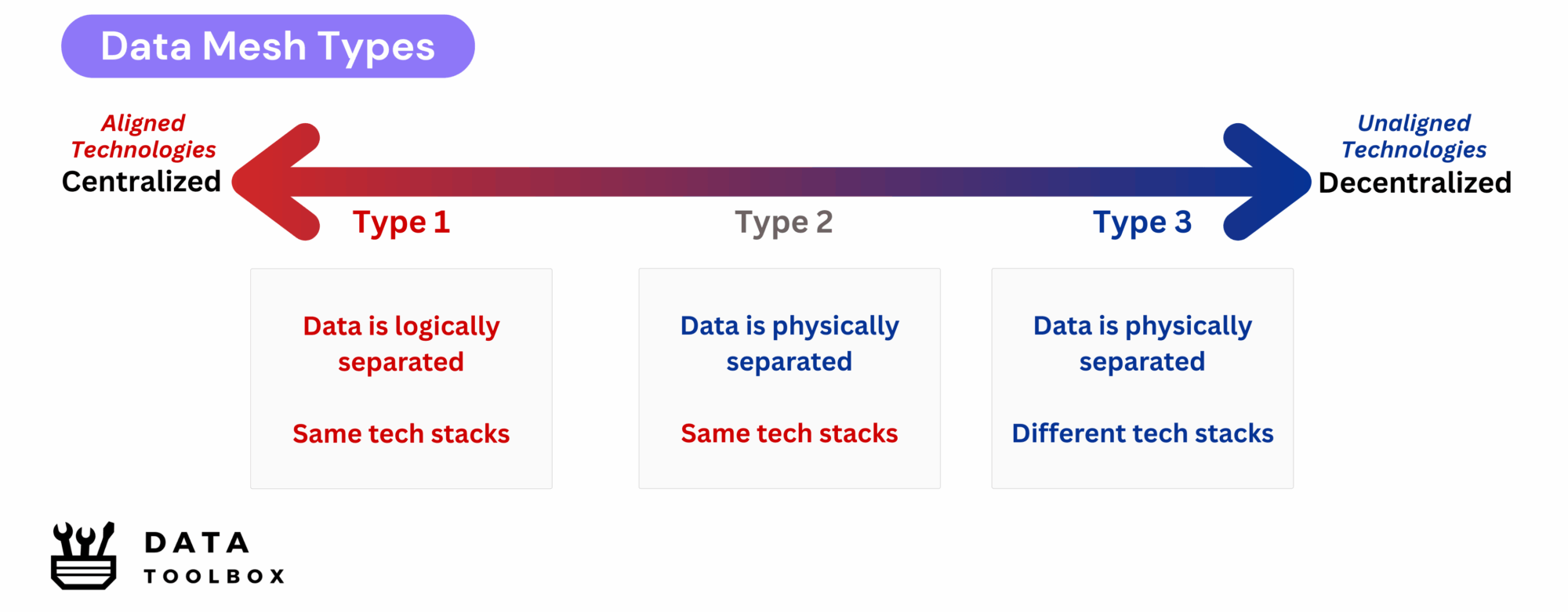
Let’s now move from theory to practice ! What does data mesh look like in real-life deployments? Here are the 3 main types of topologies often discussed:
- Mesh Type 1: Logical Decentralization, Aligned Technologies
– All domains use the same tech stack, including storage, ETL tools, MDM, and security.
– Data is logically separated (using folders, namespaces, or catalogs) but stored in the same shared platform. - Mesh Type 2: Physical Storage Separation, Aligned Technologies
– Each domain owns its own storage, but uses the same core stack and standards.
– This provides more autonomy but comes with added operational complexity. - Mesh Type 3: Full Decentralization
– Each domain chooses its own infrastructure, cloud provider, storage format, and ETL stack.
– While this gives full freedom, it leads to interoperability and cost issues.
As you might expect, Mesh Type 3 is mostly theoretical. In practice, it’s extremely difficult (and expensive…) to run one data domain on Azure, another on GCP, each with different tooling. This is why Data Mesh should be seen as a spectrum between centralization and decentralization. You can’t have full independence without trade-offs.
Real-World Implementation
Let’s begin by taking a practical example: a very large company (e.g., S&P 500-style) with multiple business units across regions. A realistic data mesh implementation could look like this:
- A Global Data Office defines enterprise-wide standards (e.g. business term definitions, quality rules, governance). → Principle 4
- A Group Data Lakehouse is shared, but partitioned by business unit (folders, namespaces, catalogs). → Principle 3
- Each Business Unit of each region manages its own stack (ETL tools, BI, security, MDM), owns its own data, and publishes data products in the group data lakehouse. → Principles 1&2
- A central IT/platform team provides self-service capabilities and blueprints with an approved tech stack. → Principle 3
Wait, wait, wait… ✋ ! At this moment, it’s important to step back and ask: how does Data Mesh fit into the broader data architecture landscape ? What about other models like data lakehouse or data fabric?
❓Problem : This is where many get confused, especially when they try to compare these approaches directly, when in fact they often address different issues.
Let’s clarify a misconception: Data Mesh and Data Fabric (or other physical architectures) are not competing models. In fact, they can complement each other. Imagine each business unit (BU) operates its own data domain and cannot legally merge their data in a single place:
- Domain A uses a Snowflake data warehouse
- Domain B uses a Databricks Lakehouse
- Domain C stores data in an on-premises Data Lake
At the same time, a central function like the Executive Committee (ExCo) requires a consolidated view of data across all domains.
In this context:
- Data Mesh provides the organizational framework. It defines who owns which data, distributes responsibilities across domains, and makes each BU accountable for producing and maintaining its own data products.
- Data Fabric serves as the technical layer that connects everything. It enables unified data discovery, access, lineage, and governance across these distributed systems, whether the underlying platform is Snowflake, Databricks, or an on-prem data lake. It can also facilitate the delivery of a consolidated view for the ExCo.
Myths and Misconceptions
Sometimes, for certain speakers (or let’s be honest, vendors), Data Mesh gets thrown around as a buzzword 🐝, a magic tool for all your problem. Let’s clear up a few common misconceptions:
- It solves all data problems → No. It creates new ones. More autonomy means more complexity to manage.
- It replaces your data warehouse or lake, so it’s efficient ! → False. You’ll likely end up with more, not fewer, storage layers (because of multiple data domains).
- It’s easier than centralized models → It’s not. It’s harder to enforce consistency when having independent teams.
- It means decentralizing everything → No. You still need central governance and shared platforms.
- It’s the same as Data Fabric → Those are completely different approaches : one is organizational, second is technological.

Let’s be honest ! Full data mesh adoption is NOT HAPPENING in most companies today. Here are some reasons why:
- Not every domain has a data team. Functions like HR, procurement, or even sales often don’t have dedicated a data team. Assuming every domain can take full ownership of its data scope is unrealistic…
- Most analytics products span multiple domains. Who owns a dashboard combining data from HR, Finance, and CRM? Cross data-domain products are the norm, not the exception !
- Is Single Version of the Truth dead ? Back in the 90s, data warehouses were designed to unify and standardize data. Are we now breaking that apart again by dividing everything into isolated domains?
- Data integration is still hard. Different domains have different identifiers, naming conventions, levels of quality, etc.
- Governance is already hard with one central team. Now imagine trying to enforce standards across ten separate teams with different levels of maturity.
- No human resources here. Even centralized data teams struggle to hire skilled worker. Expecting each domain to staff its own data team just isn’t realistic.
- And what about the cost ? Data Mesh sounds great in theory, many early discussions ignored the financial and operational implications.
Kickstarting Your Data Mesh: A Quick Guide
After everything we’ve discussed, if you believe setting up a data mesh will bring real value to your company, here’s a simple checklist to help you get started quickly without getting lost in complexity.
Operational checklist:
- Map Your Domains: Build a live inventory of datasets, pipelines, and dashboards. Assign clear owners to ensure accountability.
- Publish the RACI: Define who decides, does, reviews, and is informed. Store the matrix in your wiki and link it in every kickoff.
- Standardise the Data-Product Template: Use a versioned template covering schema, freshness, lineage, and SLAs. Every new product must follow it.
- Provide the Self-Service Platform: Offer a prebuilt toolbox—catalogue, CI/CD, observability, so teams focus on logic, not plumbing 🪠!
- Enforce Federated Governance: Embed controls like PII masking and access policies directly into pipelines. Make compliance checks automatic.
To conclude
Data Mesh is not an all-or-nothing model and should not be used everywhere ! Yes, it brings useful principles : clearer ownership, domain accountability, and more.
But the truth is that a lot of organizations aren’t ready. They don’t have the structure, the teams, or the culture to make a full data mesh work. And pretending otherwise just leads to over-engineered systems, fragmented platforms, and governance issues !
You don’t need to have a Data Mesh to improve your data architecture and become data-driven. And don’t forget :
- Where centralization still brings value → keep it (SVOT, MDM, Fabric) .
- Where decentralization is necessary → structure it (Mesh principles).
- And where alignment is missing → fix it before scaling anything.