

Introduction
When I first heard the term Data Quality (DQ), I rolled my eyes 🙄, It sounded boring… Bureaucratic-Tracking completeness KPIs, chasing missing fields, or asking upstream teams to “click the right buttons” on their front-end apps ? Really 🥱 ?
That’s not my job. I’m a Data Analyst! A Data Engineer! An ML Engineer! I build dashboards, models, pipelines. I’m not Mr. Clean.
But I was wrong! Because there’s one universal truth in data: Garbage In = Garbage Out 🗑️.
If the input data is wrong, your shiny sales dashboard is lying to your CFO. Your churn prediction model is chasing the wrong customers and your ML pipeline becomes a waste of compute and cloud credits.
What Does “Good Data” Even Mean?
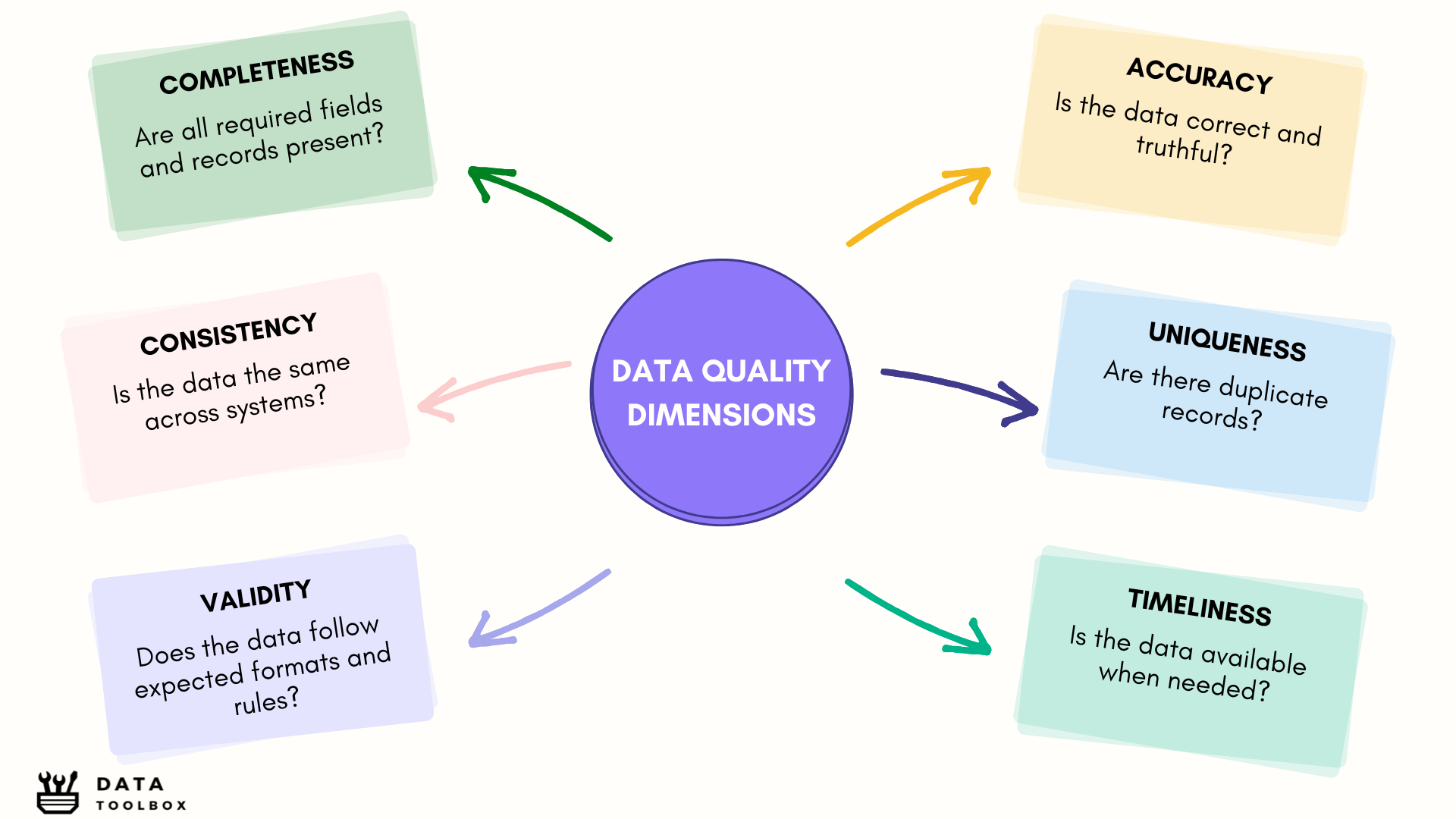
Before talking about analytics or AI, the shiny things that everyone wants, let’s talk about something more foundational (but forgotten !): data quality. If your data isn’t solid, everything built on top of it becomes unreliable. Data Quality generally comes down to 6 key dimensions, each one covering a specific aspect of what makes data trustworthy, usable, and fit for purpose.
Here’s a quick overview of the dimensions :
- Completeness
It measures whether all required data is available, including mandatory fields and expected records.
→ Missing contract dates or IDs can break your analysis. - Accuracy
It refers to the degree to which data correctly describes the real-world object or event it represents.
→ Incorrect values (e.g., wrong prices or names) lead to false insights. - Consistency
It checks whether data is uniform across different systems or datasets.
→ A customer marked “active” in CRM but “inactive” in billing? That’s a problem. - Timeliness
It refers to how up-to-date and available data is when it’s needed.
→ Late data leads to late or missed decisions. - Validity
It ensures that data follows the correct format, type, and business rules.
→ A phone number with letters or a date field saying “N/A” isn’t valid. - Uniqueness
It checks that each entity appears only once in the dataset, with no duplicates.
→ Duplicate customers = double counting, wasted marketing effort.
I’ve listed the six most “widely used” dimensions, but others can be added, like integrity or coherence. Don’t forget, it all depends on your data context and needs !
It’s a Process Problem First

Data quality doesn’t start with tools. It starts between the chair and the keyboard. It’s a people and process issue long before it’s a tooling one.
The truth is, most data issues come from upstream systems, where the data is born. These are often transactional systems (CRMs, ERPs, websites, mobile apps). And they rely on human inputs. Yes, real people… who make real mistakes.
Think of it like this:
- A customer types “Alexis” instead of “Alexi” → now you’ve got duplicate records.
- An employee skips a mandatory field in the app → now your data is incomplete.
- A product is marked “inactive” in one system, “active” in another → now your dashboard is misleading.
And it doesn’t stop there. Even within the data platform, bad transformations, failed pipelines, or schema mismatches can silently corrupt your data. Every time data is copied from one system to another, there’s a risk of degradation.
Then, Bring in the Right Tools
Once your processes are aligned and your teams understand why data quality matters, then it’s time to bring in the tools.
Let’s be clear, tools don’t fix broken habits. But they do help scale good practices, automate checks, and empower teams to take ownership of data quality without burning out.
Here are the main categories worth knowing:
- 🔍 Data Quality Monitors: Enforce rules like “no nulls in ‘Customer ID’”, “timestamps must be recent”, or “price must be positive”. They help catch obvious issues before they escalate.
- 📚 Data Catalogs: Provide visibility into your data’s lineage, ownership, and context. When you need to ask “Where did this come from?” or “Can I trust it?”, the catalog is your source of truth.
- 🧠 Automated Anomaly Detection: Use machine learning to surface strange or unexpected patterns in your data, without having to define every rule manually.
Some popular tools include: Great Expectations, Monte Carlo, Collibra, Atlan, and DataHub.
Real-World Nightmares
Want some proof that data quality matters? Here are real cases I’ve witnessed:
💥 Case #1: Compliance Breach from Duplicated Records
A customer had two contracts (health and life insurance) and opted out of physical mail through the company’s main web portal. But a tiny space in their name on one contract caused the system to treat them as two different people.
Result? The health contract was updated, but the life insurance one wasn’t, and they received a physical letter about their life insurance, right in the middle of their divorce proceedings… where the wrong person opened the mailbox 📬.
➡️ Cue legal action.
💥 Case #2: Bad Data, Bad Decisions
An e-commerce company launched a customer segmentation model. The problem? 15% of so-called “inactive” users were very much active, they were browsing from mobile, but mobile tracking tags were missing 📱.
➡️ Marketing spend misfired, retention numbers misread.
💥 Case #3: A Pipeline Gone Rogue
During a cloud migration, a misconfigured transformation script started duplicating 10% of all transactions, for a full month. Dashboards showed inflated revenue across the board.
Nobody noticed… until the CFO did 😠.
➡️ Not a fun meeting.
Conclusion: Data Quality = Data Trust

Let’s be real, no matter how cool your dashboards look or how many layers your neural net has, if the data is dirty, your entire stack is just polishing a 💩.
So yes, time to channel your inner Mr. Clean: 🧼 Scrub scrub, clean clean, I want it sparkling and smelling like lavender !
Because otherwise? Your dashboard is lying, your model is hallucinating, and your AI is out there eating trippy mushrooms 🍄 trying to predict customer churn based on moon phases :D.
Data Quality might seem like the boring, unloved stepchild of the data world, but we’ve seen today that:
- It rests on 6 essential dimensions.
- It’s mostly a process issue, not a tooling problem.
- And when it breaks, it comes back like a boomerang, to smack you right in the face.