

In the global overview, we described Data Fabric as a logical layer that integrates your entire data landscape 🏞️ by connecting and abstracting physical architectures like data warehouses, data lakes, and data lakehouses. It’s like a meta-architecture, that abstracts data complexity and promotes unified access and governance without centralizing physical storage.
Sooo, now let’s dive in 🚀! How does it actually work, what are the design principles, which are the patterns, and what are the real-world tools?
Quick Recap ↻
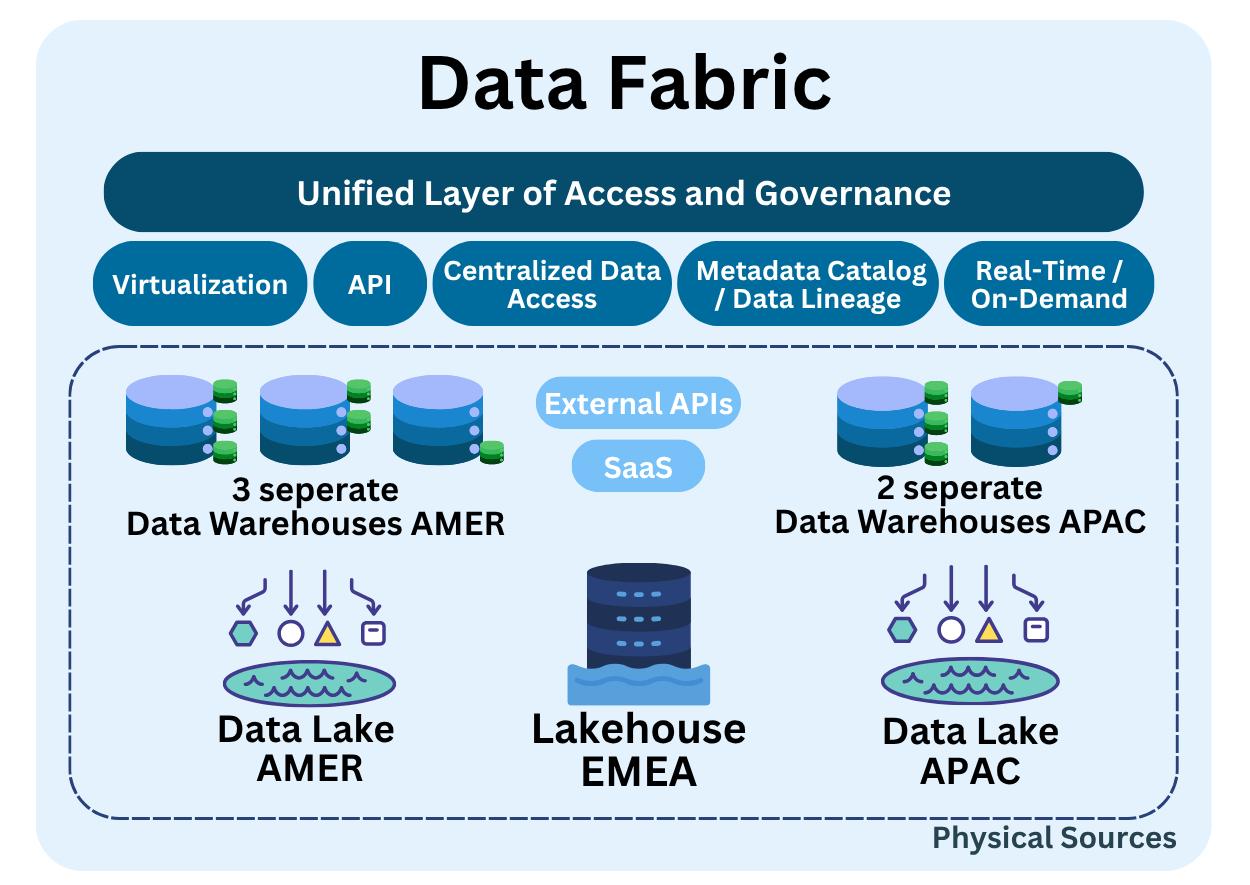
Data Fabric is a logical architecture that unifies access to distributed data systems through virtualization, metadata-driven orchestration, and centralized governance. Rather than storing data in one place, it provides a consistent way to discover, secure, govern, and access data, no matter where it resides.
In contrast to physical storage architectures, Data Fabric overlays your existing landscape and provides intelligence on top of it 🔝.
Why was this architecture created?
For years, traditional data architectures have aimed to centralize everything into a single source of truth, typically warehouses or more recently, lakehouses. The idea was straightforward: bring all data into one place to simplify analytics, governance, and operationalization. But in reality, this centralized approach quickly becomes impractical, especially in complex, modern enterprise environments.
Why Centralized Solutions Break Down ?
- Multi-region deployments: In global organizations, data is naturally distributed across regions for latency, operational, or legal reasons. Centralizing all data into a single repository becomes not only expensive, but often technically unfeasible.
- Regulatory constraints (e.g., GDPR): Regulatory requirements demand that certain data remain within specific jurisdictions. Copying or moving this data to a central location can violate compliance mandates and expose the organization to legal risk.
- Organizational autonomy: Large corporations are generally organized into separate domains or business units, each with its own priorities, systems, and roadmaps, so imposing a single centralized model seldom aligns with day-to-day reality, which is why many organizations turn to a multi-tenant approach where every unit operates its own data warehouse or lakehouse.
- Cloud/on-prem/SaaS fragmentation: Today’s IT landscapes are highly fragmented across public clouds, on-premise systems, and SaaS platforms. This leads to pipeline sprawl, isolated data silos, and fragmented metadata management practices.
- Frequent mergers and acquisitions: Each merger or acquisition brings in new, often incompatible, analytical systems. Assuming all this can be harmonized into a single lake or warehouse is now widely seen as unrealistic.
This fragmentation results in redundant data movement, governance gaps, and inconsistent metadata practices when multiple, independent analytical storage systems, such as data warehouses or data lakes, are used. This is exactly the context in which Data Fabric has emerged: not as a replacement for existing systems, but as an intelligent layer that connects them.
Rather than enforcing centralization, it focuses on enabling interoperability across disparate sources, automating data management through metadata-driven processes, enforcing unified governance and access policies, and supporting both real-time and on-demand data integration.
Core Architectural Principles
At the heart of every real Data Fabric are five foundational principles. These are the foundational elements that make the architecture work in practice:
- Data Virtualization: Enables seamless access to data across multiple systems, such as data warehouses, lakes, and APIs, without physically moving or duplicating it. It feels like everything is in one place, even when it’s not 👻.
- Standardized API-Based Access: Data is exposed through consistent and secure interfaces like REST, SQL, or JDBC, allowing users and applications to query any source in a unified way.
- Centralized Data Access Policies: Access is governed through enterprise-wide rules including RBAC, encryption, data classification, and user authentication. These policies ensure security, regulatory compliance, and organizational trust.
- Metadata Catalog and Lineage: A centralized catalog captures data structure, business definitions, ownership, and relationships across the ecosystem. It enables users to understand what data exists and how to use it. Lineage provides visibility into how data is created, transformed, and consumed, supporting transparency and governance.
- Real-Time or On-Demand Access: Data is available when it’s needed, whether for real-time analytics, dashboards, or API-driven services, eliminating the need for batch processes or manual transfers.
Benefits and Trade-offs
Choosing a Data Fabric approach can be a strong fit for your organization, especially if centralized solutions are impractical due to organizational complexity or regulatory constraints. Like any architectural decision, it brings clear benefits along with important trade-offs to evaluate.
✅ Data Fabric pros:
- Faster data discovery and access: Unified APIs and active metadata make it easier for teams to find and use the right data quickly.
- No need to move or duplicate data: Data is accessed in place, reducing storage costs and avoiding complex migration efforts.
- Stronger governance and metadata consistency: Centralized policies and metadata catalogs improve compliance, data quality, and trust.
⚠️ Data Fabric cons:
- Not plug-and-play: Setting up connectors, metadata pipelines, and policies takes time and coordination.
- Latency risks with virtualization: Federated queries can be slow; real-time use cases may still need caching or materialization.
🚸 Careful! Data Fabric is primarily designed for unified data access and reading across sources. While it can support writing operations, such as propagating transformed data to target systems, this is not its core purpose. In most implementations, write operations are limited, customized, and tightly controlled, making them the exception rather than the rule.
Real-World Tools
As we have seen, a Data Fabric is a virtual layer that sits above everything else, it is not delivered as one all-in-one product, but is assembled from several tools that work together to form a seamless layer. For instance, consider:
- Integration, governance, and metadata management: Informatica Intelligent Data Management Cloud, Talend Data Fabric, IBM Cloud Pak for Data
- Cataloging and lineage: Collibra, Atlas, Amundsen, Microsoft Purview, DataHub
- Access and virtualization: Presto, Trino, Dremio
- Orchestration, transformation, and observability: Airflow, Dagster, dbt, Meltano
- Metadata and Observability: Monte Carlo, Great Expectations, Soda, Informatica IDMC
- Policy and Security: Privacera, Okera, Unity Catalog, Ranger
⚠️ About Microsoft Fabric: Fabric implements many Data Fabric principles within the Microsoft cloud stack, including: unifying data lakes, warehouses, and lakehouses (OneLake), built-in governance and cataloging (via Purview), metadata and semantic modeling (Power BI / Lakehouse integration).
But it is not a truly vendor-agnostic Data Fabric (as defined by Gartner). It offers deep value for Microsoft-based enterprises, but its cross-platform openness is limited, which can hinder flexibility in multi-cloud or diverse data landscapes.
To conclude, is this architecture still relevant?

Definitely, particularly in today’s hybrid, multi-cloud, SaaS-heavy landscape. Data Fabric is not a substitute for your physical data infrastructure, it unifies them and provides governance-first access across silos.
It simplifies access to distributed data, enabling faster innovation while maintaining trust, security, and flexibility. However, implementation can be complex, there is no single perfect tool, and success relies on aligning architecture, governance, and organizational culture.
👉 For an organizational perspective on data, explore Data Mesh in our upcoming architectural deep dives.