

In our high-level article, we explored how Hybrid Data Warehousing merges the structure of a traditional DWH with the flexibility of a Data Lake, offering a middle path between rigid modeling and data swamp 🐸. Now, let’s go deeper: into the architectural principles, real-world design patterns, and challenges of this hybrid architecture.
Quick Recap ↻
A Hybrid Data Warehouse brings together two coexisting ecosystems:
- A Data Warehouse built for governance, structured data, and SQL-based consumption (BI, KPIs, dashboards).
- A Data Lake built for flexibility and scale, supporting big data processing, machine learning, and the handling of semi-structured and unstructured data, with native support for Python, Scala, and other languages.
In this model, data flows into either or both systems depending on the usecase, purpose, and performance. The goal isn’t to duplicate blindly but to balance control and agility.
Let’s talk about the emergence of the Data Lake first
In the mid-2000s, data started growing faster than traditional databases could handle. Companies were collecting more information than ever: web logs, user clicks, mobile app events, social data, and needed a new way to store and process it all.
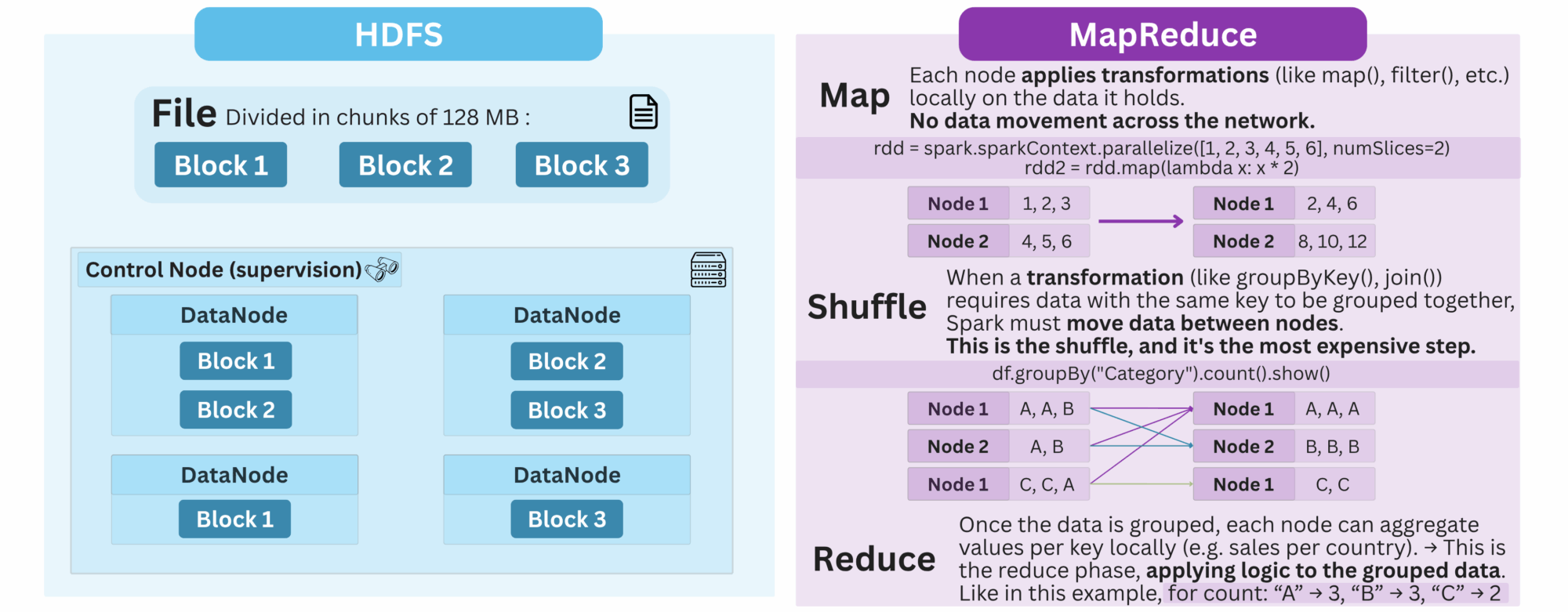
Welcome, Hadoop 👋 ! Not a single tool, but a broader ecosystem, Hadoop was inspired by Google’s internal technologies like the Google File System (GFS) and MapReduce. At its core, it introduced two fundamental components:
- HDFS (Hadoop Distributed File System) for storing large volumes of data across a cluster of machines
- MapReduce, a programming model to process that data in parallel by breaking tasks into chunks, computing them across nodes, then aggregating the results.
This was revolutionary at the time. You could now store massive amounts of data on cheap hardware, process it in parallel, all without relying on traditional databases that cannot easily scale horizontally. That was a core foundation of what would later become the data lake: a central repository to store raw, unstructured, and structured data at scale.
However, MapReduce had limits. It was disk-based, slow, and hard to work with for anything beyond batch jobs. Enter, Spark 👋 ! Spark brought in-memory computing, which made data processing dramatically faster. It also supported more user-friendly languages like Python and Scala, making it a favorite among data scientists.
At the same time, cloud storage services like Amazon S3, Azure Data Lake Storage (ADLS), and Google Cloud Storage (GCS) emerged. These platforms allowed companies to store practically unlimited amounts of data without managing physical infrastructure, reinforcing the data lake model and pushing the modern data stack into the cloud.
So why wasn’t a data lake architecture enough?
Dump everything into the lake and analyze it later! 🚮
The rise of the Hadoop stack, and later cloud object storage, fostered the belief that data lakes would make data warehouses obsolete. But the result was unexpected: without metadata, structure, or lineage, many lakes turned into data swamps 🐸 : an ungoverned storage filled with thousands of files with no clear purpose.
On the other hand, data warehouses are excellent at supporting business reporting but struggle with modern demands such as real-time ingestion, variable schemas, and large volumes of semi-structured data.
Also, business analysts and data analysts typically work well with SQL, but tasks like setting up a Spark cluster, running Hive jobs, or structuring a metastore are more suited to data scientists (or expert data users). This created a gap between the data infrastructure and the people who actually needed insights from it. In practice, many teams couldn’t fully leverage these powerful tools because they were simply too complex for their day-to-day users
Hybrid DWH emerged as a pragmatic solution: use the DWH for reliability and trust, use the Lake for scale and flexibility, and orchestrate between them based on use case.
Core Architectural Principles
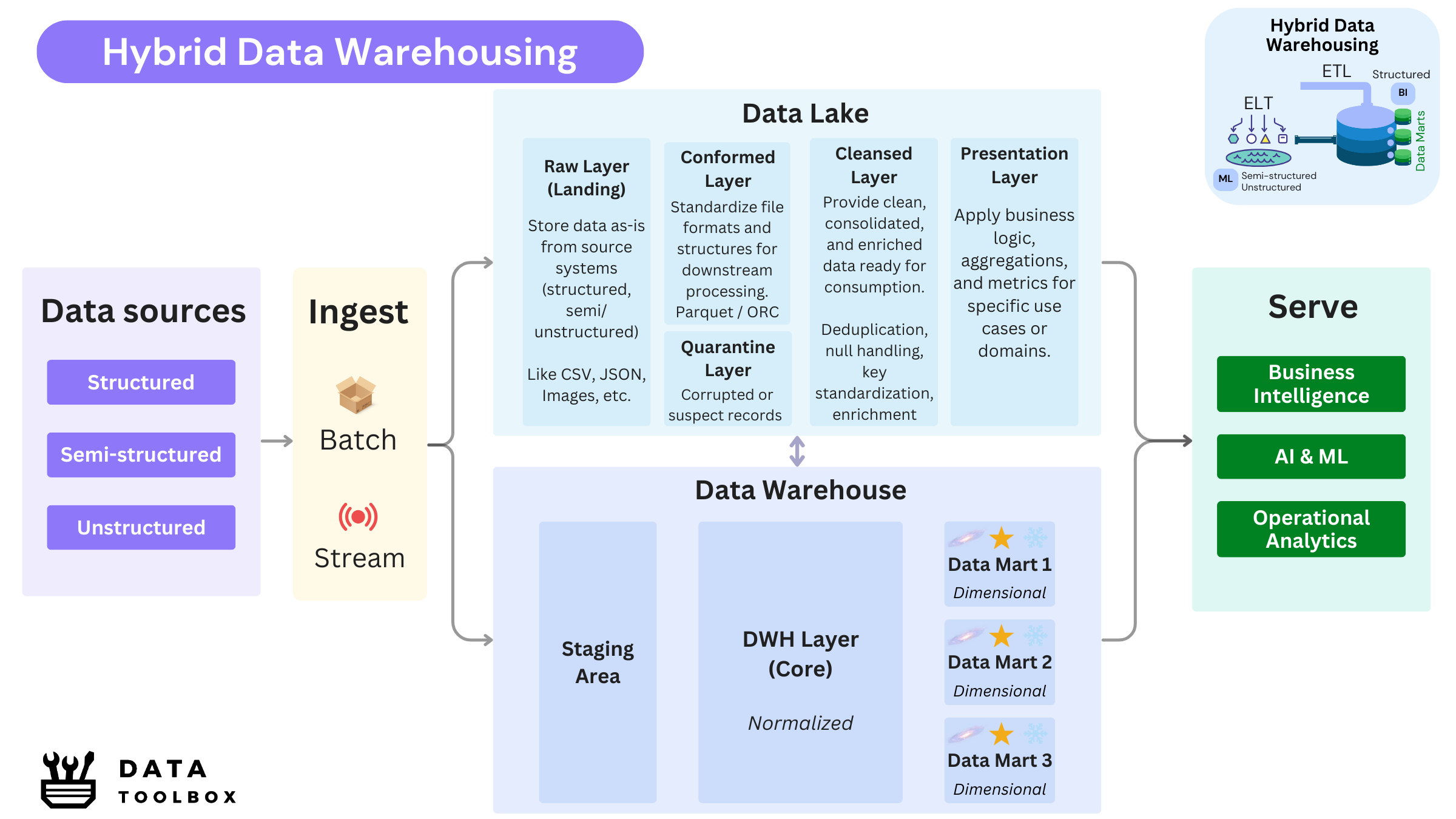
🏢 Data Warehouse Layering & Tools
We’ve already discussed the data warehouse layers and tools here in detail, but let’s do a quick recap.
Data Warehouse layers:
- 1️⃣ Staging layer: where structured raw data lands after extraction, often minimally transformed.
- 2️⃣ DWH layer (or core): where structured data is cleansed, standardized, and modelized into a normalized model (3nF-ish or Data Vault) aligned with business domains.
- 3️⃣ Data Mart layer (or presentation): where structured data is reshaped into denormalized, domain-specific views for consumption by reporting tools or dashboards.
Principal tools : BigQuery, Snowflake, Redshift, Synapse (cloud MPP); ClickHouse, Greenplum, Teradata (on-prem); etc.
🌊 Data Lake Layering & Tools
For data lakes, let’s take a more exhaustive look at the layers involved. A well-architected and properly governed data lake typically follows a layered approach:
- Raw Layer: Stores all ingested data in its original format (JSON, CSV, Avro, images, videos, etc.) as an immutable system of record. Unstructured data typically remains in this layer, while structured/semi-structured data progress through subsequent layers for processing.
- Conformed Layer: Converts raw files into standardized, columnar formats like Parquet or ORC for interoperability and performance. Non-conforming data is stored in the Quarantine Layer ⛔️.
- Cleansed Layer: Contains validated, de-duplicated, and enriched datasets, ready for downstream use.
- Presentation Layer: Applies business logic to produce consolidated datasets optimized for end-user consumption, dashboards or ML pipelines.
Principal tools:
- Storage: Amazon S3, Azure Data Lake Storage (ADLS), Google Cloud Storage (GCS), Hadoop Distributed File System (HDFS)
- Compute: Spark (Swiss Army knife 🛠️), Flink (streaming-first ⚡), Trino/Presto (SQL engines 🔍) , Hive (legacy batch 🏚️)
- Formats: Parquet, ORC, etc.
Multi-Tenant vs Single-Tenant
A multi-tenant approach physically separates data by business unit, region, or legal entity, offering more control but increasing complexity and duplication.
In a single-tenant architecture, all data is stored in one unified data lake with logical separation by folder, schema, or metadata. This simplifies governance and enables cross-domain analytics, but reduces autonomy and can create regulatory issues. Thus, many organizations use virtualization techniques (e.g. RBAC, RLS) to simulate multi-tenancy in one data lake.
However, regulations like GDPR or U.S. privacy law (like CCPA or HIPAA) may prohibit even the virtual co-location of sensitive data. This often requires physically separating data across regions, cloud accounts, or storage layers, turning the use of multiple data lakes from a design preference into a regulatory necessity.
Overview of Hybrid Data Warehouse Patterns
Pattern 1: “Lake as Source of Truth”
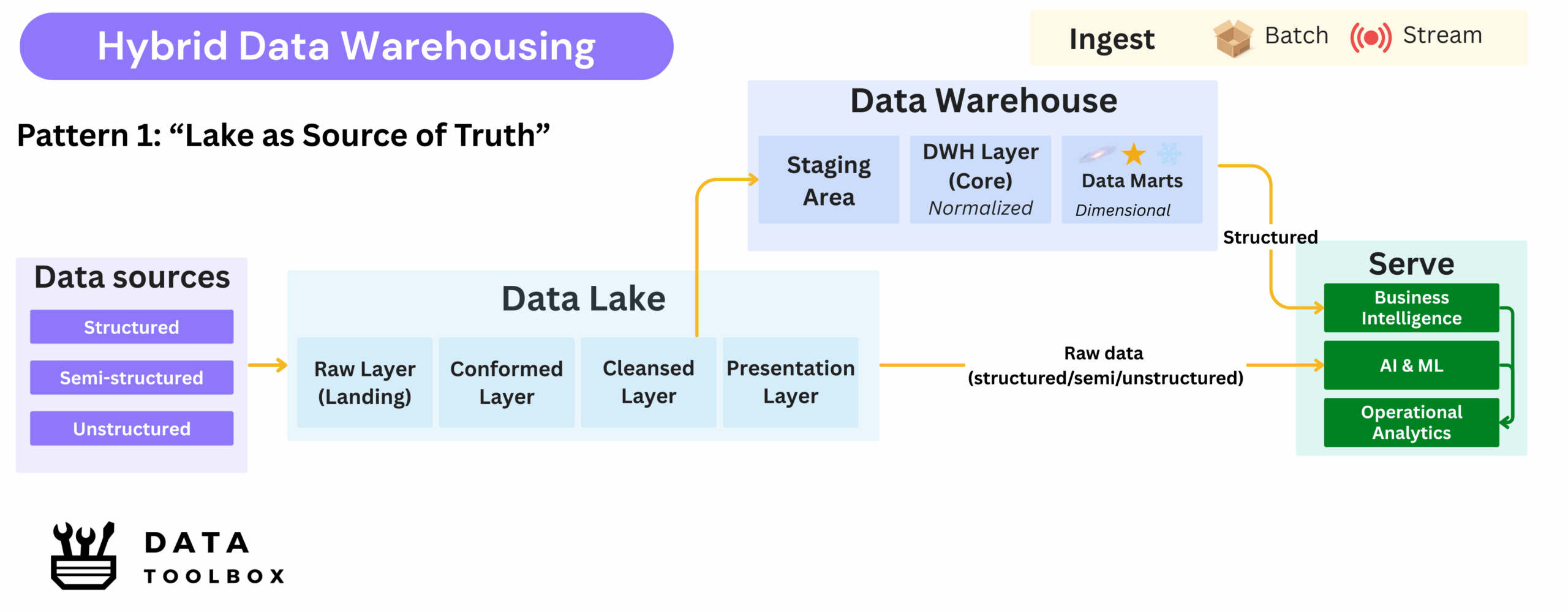
All raw data, structured, semi-structured, and unstructured, is first ingested into the data lake. Only consolidated, structured subsets are then transferred into the data warehouse for downstream analytics and reporting.
Key Advantages ✅:
- Full auditability and raw data retention for compliance and replayability
- Enables recovery from ETL failures without re-ingesting source data
- Centralized ingestion pipelines simplify onboarding new data sources
Trade-Offs ⚠️:
- Introduces data duplication, with the same datasets stored in two systems
- Schema fidelity impacts data quality and metadata richness: consuming raw Parquet files in a DWH typically provides less contextual information than ingesting data directly from the original source with full metadata.
Pattern 2: Parallel Ingestion
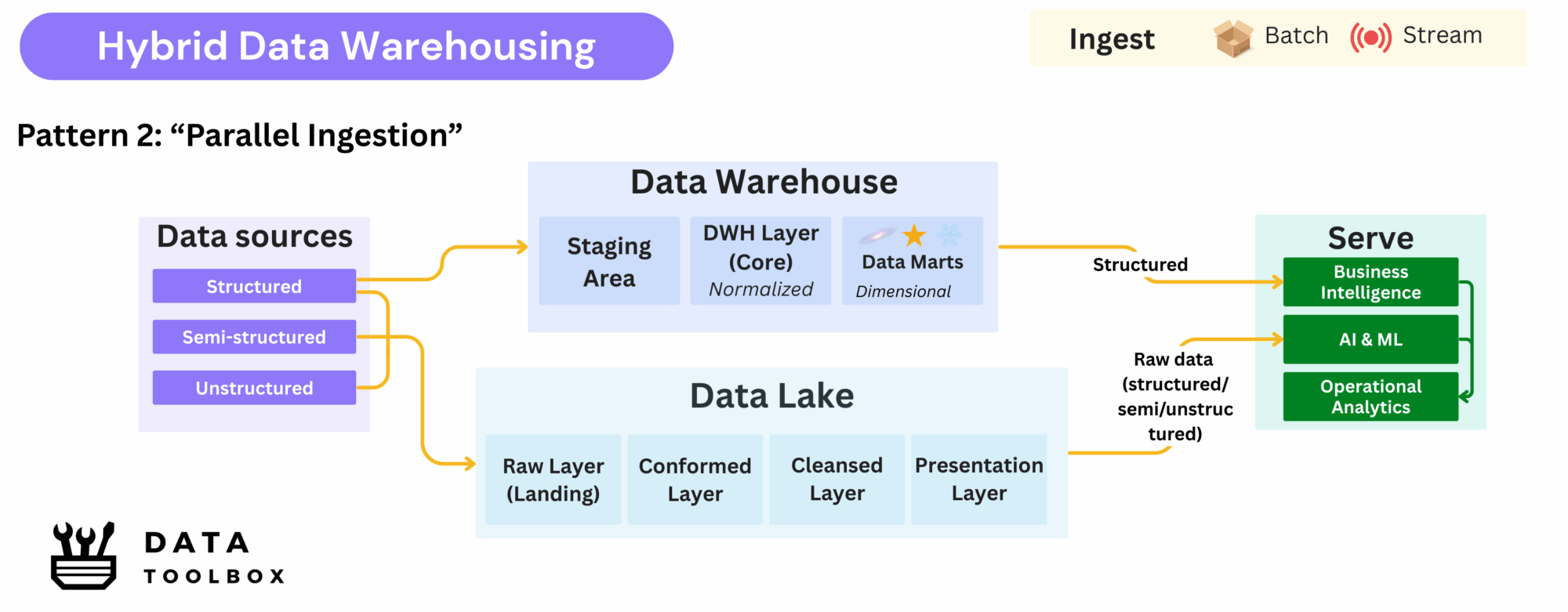
Structured data is simultaneously ingested into both the data lake and the data warehouse, enabling distinct use cases without bottlenecks.
Key Advantages ✅:
- Preserves rich schema metadata within the Data Warehouse
- Keeps raw data accessible for data science and exploratory workloads
- Avoids unnecessary transformations just to stage data in the lake
Trade-Offs ⚠️:
- Introduces data duplication, with the same datasets stored in two systems
- Requires synchronization mechanisms to maintain consistency
Pattern 3: Reverse Lakehouse
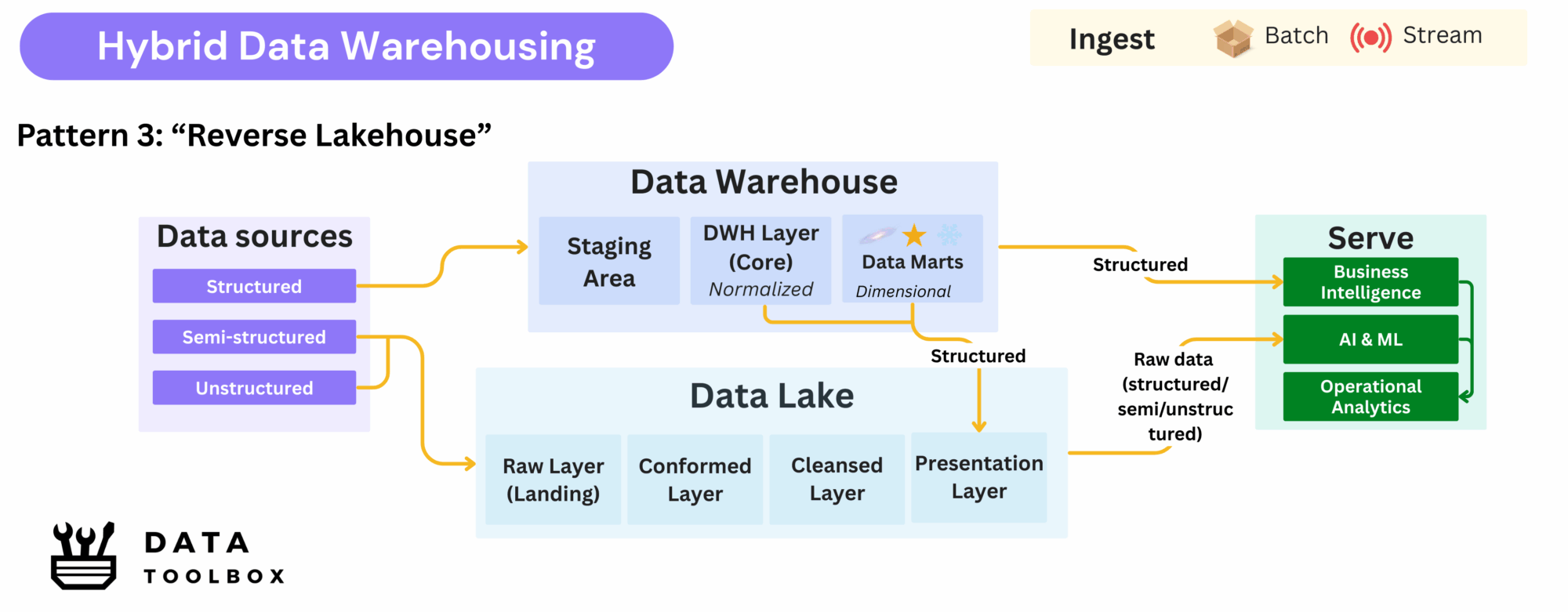
Consolidated data from the data warehouse is exported back into the data lake to power machine learning and data product pipelines.
Key Advantages ✅:
- Ensures ML models use trusted, high-quality datasets
- Minimizes risk from inconsistent or incomplete training data
- Bridges the gap between BI and AI workflows
Trade-Offs ⚠️:
- Introduces data duplication, with the same datasets stored in two systems
- Requires strong governance of downstream lake datasets
The problem here.

In hybrid setups, we combine the strengths of DWH and Data Lake technologies to support both BI and AI on the same platform, but this comes with trade-offs:
- Two storage solutions = more people involved, higher costs
- Complex pipeline orchestration
- Fragmented governance and metadata
- Different storage formats and schemas
- Different update cadences
To conclude, is this architecture still relevant?
Hybrid Data Warehousing lets you mix the best tools for the job, whether it’s BI dashboards or machine learning workflows. It might be surprising, but a good number of large companies are operating at this stage today, but the problem of duplication, governance, and complexity are real challenges.
That’s why many organizations are now turning to architectures like Data Lakehouse or Data Fabric, or adopting approaches like Data Virtualization, all aiming to provide a more unified and streamlined data foundation.
👉 Stay tuned for our next deep dive: Architectural Deep Dive: Data Lakehouse or check out the global overview.