

In our high-level article, we explored the broader landscape of modern data architectures: Traditional Data Warehousing, Hybrid Data Warehousing, Data Lakehouse, Data Fabric, and Data Mesh. Today, we’re diving deep 🤿 into the one that started it all: Traditional Data Warehousing.
Quick Recap ↻
Traditional data warehousing follows a structured, schema-on-write approach. Data is ingested through ETL pipelines into a centralized data warehouse, often complemented by downstream data marts. This architecture ensures a Single Version of Truth (SVOT) by consolidating, transforming, and standardizing data before it’s used for analysis.
Designed for structured data, this architecture supports historical analysis through slowly changing dimensions (SCDs). It emphasizes business needs, with dedicated ETL processes ensuring up-to-date and reliable data.
Why was this architecture created?
Before the explosion of cloud-native data platforms and schema-on-read paradigms, companies struggled with a common issue: operational systems were not designed for analytics. Running reports directly on operational systems slowed them down and produced inconsistent results (see why you can’t mix transactional and analytical).
Data warehouses emerged to solve these problems, providing a dedicated environment where data could be integrated, cleansed, standardized, and modeled. More importantly, it enabled organizations to build a Single Version of the Truth (SVOT), a reliable, unified view of enterprise data.
This architecture was often bundled as an all-in-one solution, combining ETL, storage, reporting, and dashboarding into a single package (like SSAS, SSIS, SSRS in the old BI era 🏺 or like the Oracle/Exadata stack). Although today we tend to decouple these components, the architectural logic remains influential.
A Brief History of Warehousing Philosophies
The classic DWH structure that we presented, with its staging, core, and presentation layers, is the result of decades of architectural evolution. It didn’t emerge overnight; it grew from a rich and sometimes conflicting history 🤼 of modeling philosophies, led by key figures like Bill Inmon and Ralph Kimball.
For years, their approaches were debated and contrasted, until many organizations eventually landed on pragmatic hybrids that draw from both.
🥊 Contender #1: Bill Inmon
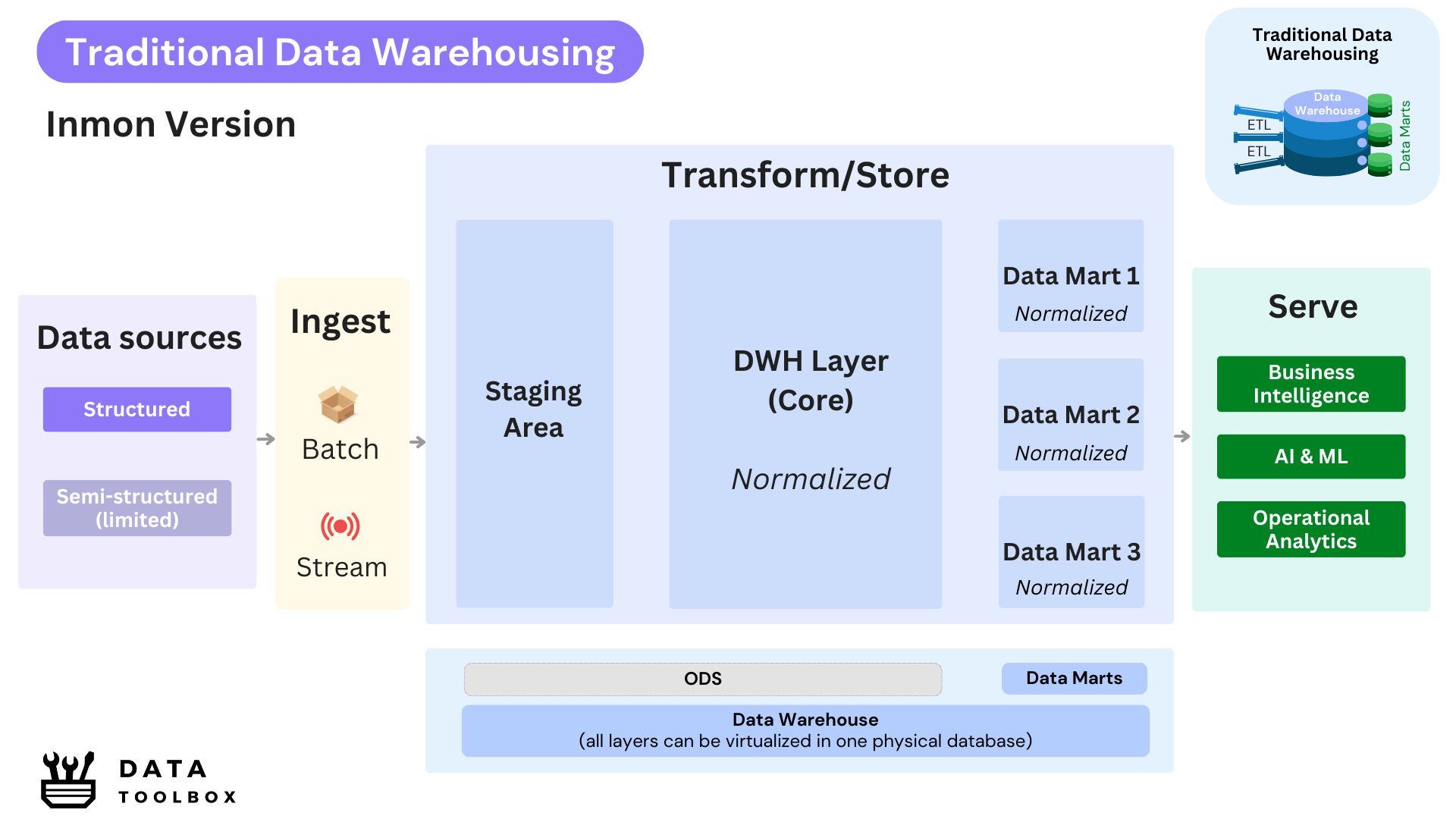
In his foundational book Building the Data Warehouse (1992), Bill Inmon introduced a top-down methodology in which a fully normalized Enterprise Data Warehouse (EDW) is designed and implemented first as the central repository. The architecture is typically structured in layers, starting with a staging area that collects raw data from source systems before any transformation, and followed by the core layer itself, where data is cleaned, integrated, and modeled to ensure consistency and traceability. From this unified and governed foundation, dependent data marts are created to support specific business domains. His initial approach emphasizes enterprise-wide integration, strong data quality, and a consistent view of information across the organization.
Inmon’s thinking was shaped by the technological constraints of the time. Storage was expensive, compute resources were limited, and in-memory processing was not viable (really expensive 💰!). As such, having redundant data was considered wasteful and impractical. That’s why Inmon championed normalized models and centralized control in the data warehouse layer. The data marts were also normalized and used in conjunction with old OLAP cubes, which were disk-based (not like today’s in-memory semantic layers), reducing data duplication while supporting multidimensional analysis through pre-aggregated and indexed structures.
🥊 Contender #2: Kimball (Bottom-Up)
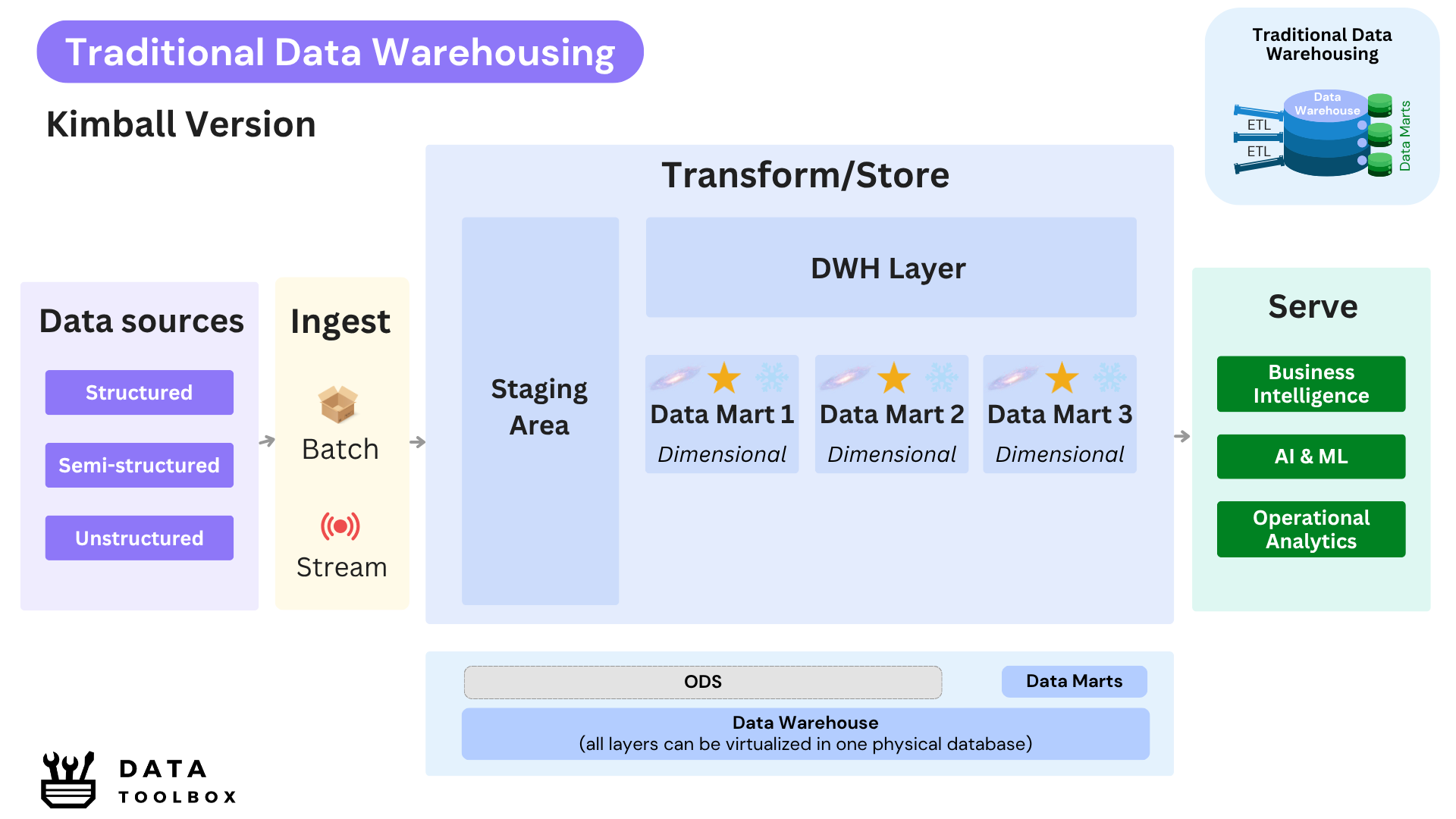
Ralph Kimball proposed a more agile methodology in The Data Warehouse Toolkit (1996), he advocated for the creation of dimensional data marts directly aligned with business needs. He was the first to popularize denormalized models such as star ⭐ and snowflake ❄️ schemas, designed to simplify queries and ultimately improve read performance.
He also relied, like Inmon, on a staging layer to collect raw data from source systems before transformation. However, instead of building a centralized EDW up front, his approach allowed teams to deliver value incrementally by developing focused data marts, each tailored to a specific analytical domain or data product. These data marts were directly denormalized using dimensional modeling, embracing intentional data redundancy as a trade-off for usability and speed, and enabling read-optimized access without the need for complex joins across multiple normalized tables.
🏆 Winner : Real-World Hybrid
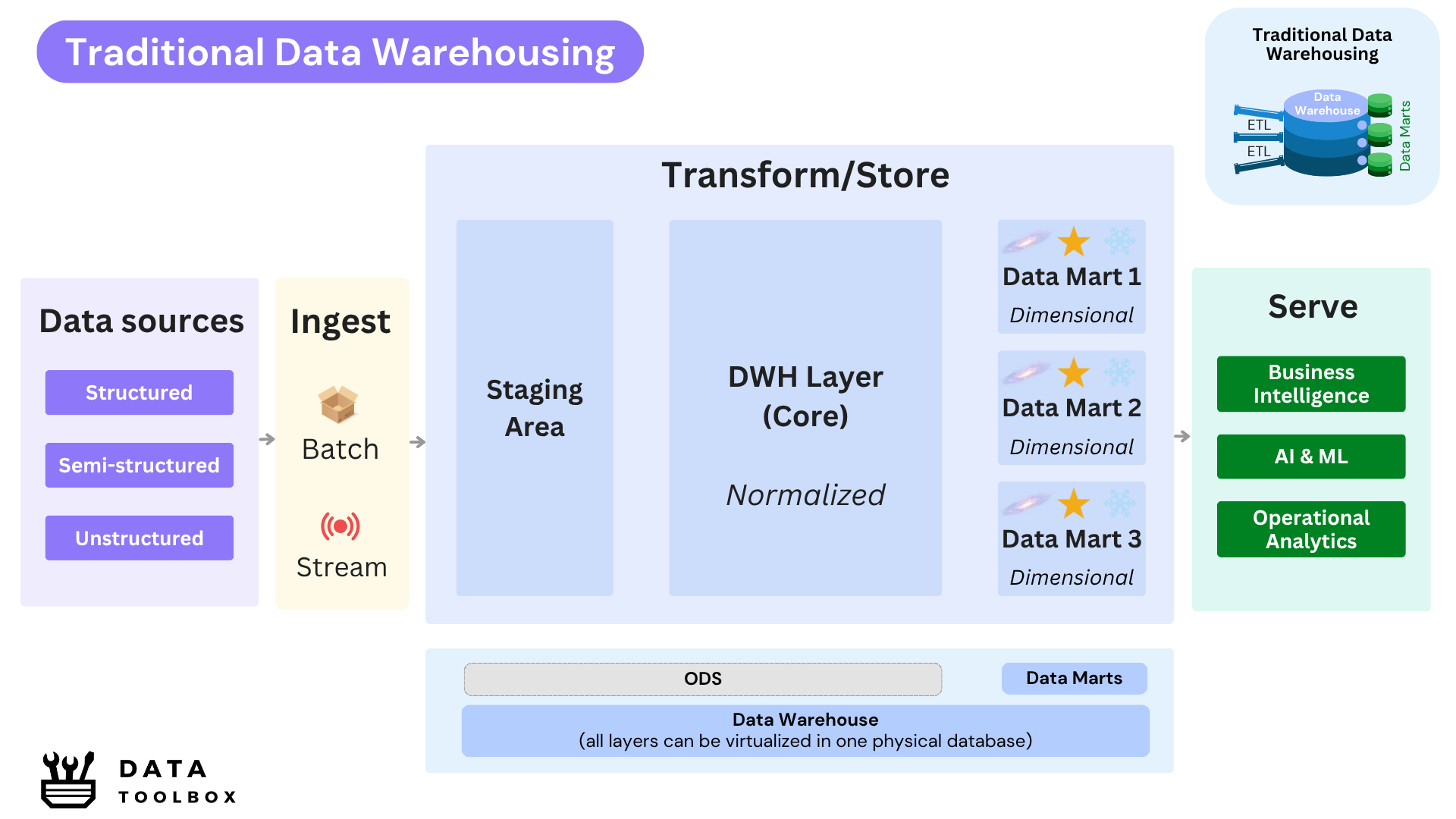
In practice, most organizations adopt a hybrid approach that blends both philosophies. A common staging layer is used upfront to ingest raw data, followed by a normalized core layer (typically modeled in 3nF or Data Vault) influenced by Inmon 🥊 to enforce consistency and governance. On top of this foundation, dimensional data marts inspired by Kimball 🥊 are developed to provide agility and deliver business-aligned insights. These marts can be physical or virtual, and are built to serve specific analytical needs efficiently.
Deep dive into layers
Let’s take a deep dive into the three core layers of the hybrid model of Data Warehouse, exploring how each contributes to data integration, consistency, and usability.
Staging Layer
ETL pipelines (like ODI, Talend or Informatica) extract data from OLTP systems using JDBC, APIs, SFTP, or CDC mechanisms. This extracted data lands in the staging layer, which acts as the raw entry point of the data warehouse.
Traditional data warehouses require structured, schema-defined input. Files like CSV or XML are parsed and mapped via ETL before landing in relational staging tables. At this stage, we do not apply any business rules, transformations, or integration logic. The goal is to land the data as-is, aligning with the source schema, with minimal technical adjustments (casting types, dropping corrupt rows).
What needs to be extracted, when, where, and by whom is defined through a data contract. It specifies schema, delivery timing, format, and validation rules. In staging, data contracts help enforce consistency and avoid ingestion issues. When certain sources have special constraints, an extra landing zone can be created to handle their specific ingestion logic separately. This setup improves traceability, quality control, and operational flexibility.
When source systems expose partitioned tables like orders_2024, orders_2025 or status-based tables such as webshop_orders, instore_orders, you have two choices: either preserve them as-is loading each table separately, or consolidate them into a single unified orders entity, enriching it with metadata fields like year or status to retain traceability. The choice depends on how closely the warehouse needs to mirror the source or enable downstream integration.
Core Layer
The core layer is the semantic and historical backbone of the warehouse. It enforces data consistency, tracks changes over time, and prepares for business consumption. It is usually modeled in 3nF or Data Vault, depending on the organization’s preference for normalization and historization.
It is usually physically stored and organized into two sublayers, which can also be segmented by country, business unit, or other dimensions:
Prepared Layer
The Prepared Layer contains cleaned and structured tables that mirror the original entities from each source system. At this stage, the data is:
- It undergoes essential cleaning steps (remove irrelevant data, column renaming, type casting, null handling, deduplication, uniqueness, constraints, etc.) to ensure technical consistency, but no business transformations or integration logic are applied yet.
- Still source-aligned: for example, tables like
customer_france,customer_germany,sales_physical_store, andsales_onlineare maintained separately. While limited regrouping may occur within a single source (like combining multiple tables from the same system), no cross-source joins or integrations are applied at this stage. - Optimized for lineage tracking, data quality checks, and reusability in downstream layers.
- If a data quality check fails, the invalid records can be redirected to a separate sublayer called the Quarantine Layer, which isolates bad data for further inspection or remediation.
The modeling strategy in the Prepared Layer depends on the nature of the data:
- Immutable data (sales, invoices, etc.) is modeled as append-only, with each record represents a fixed historical event.
- Mutable data (customers, products, etc.) is typically handled as a periodic snapshot in this layer, following the structure of the staging area. Historical tracking is intentionally deferred to the Unified Layer.
Unified Layer
This is where cross-source integration occurs:
- All entities from multiple systems or cross systems are merged into a unified view (like unified
customer,product,sales, etc.). - Surrogate keys are introduced to replace inconsistent source system identifiers and ensure referential integrity.
- Code normalization and reference mappings are applied (
FR,France,FR01→ unifiedcountry_id), enabling standardized analytics. - Conflicting semantics are reconciled, ensuring attributes like “revenue” or “status” have consistent definitions across systems.
- Master Data Management (MDM) can support this layer by providing golden records, identity resolution, and data quality enforcement for core business entities.
- This layer becomes the single source of truth for consistent, enterprise-wide entities.
Most importantly, SCD2 (or other historization techniques) is applied to mutable entities (customers, products) to track historical changes over time. Each change in an entity’s attributes creates a new version, timestamped with valid_from and valid_to, enabling point-in-time analysis, regulatory auditability, and data science use cases such as churn modeling or lifecycle segmentation.
Data Marts Layer
The final layer contains subject-specific, read-optimized models tailored for business reporting and analytics. Built from core layer, data marts are typically modeled using dimensional approaches such as wide-table, Star, Galaxy, or Snowflake schemas. Data marts can be either physical (materialized tables for read performance) or virtual (logical views).
This layer can include:
- Domain-specific marts: Aligned with organizational functions (Sales, HR, Finance, etc.).
- Product-specific marts: Designed around data products or analytics use cases, often with clear user-facing interfaces, such as APIs, dashboards, or BI tools.
Nothing beats a real-life example 🧙
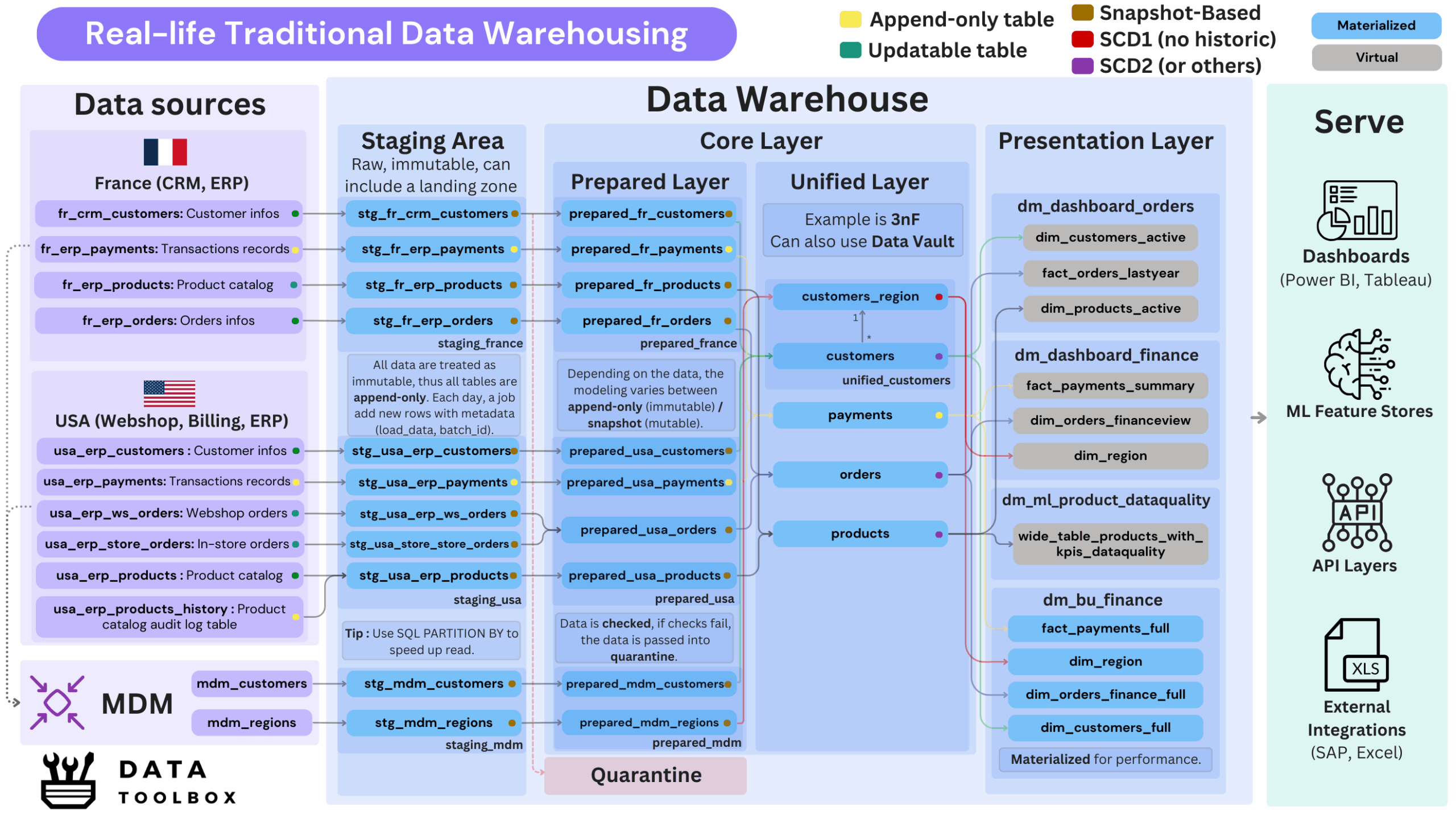
This is a dense and detailed diagram that provides an overview of a warehouse architecture. It illustrates the full data lifecycle, from raw ingestion to data serving, while highlighting the various layers and transformations involved.
To fully grasp this canvas, you need a good understanding of data mutability (append-only vs. updatable), data modeling techniques (like 3NF or SCD), and a solid background in analytical versus transactional design.
Multi-Tenant vs Single-Tenant Warehousing
One common architectural decision in traditional data warehousing is whether to adopt a multi-tenant or single-tenant approach. This decision affects how data is isolated, modeled, and governed across BU/SUs, or geographic regions.
In a single-tenant architecture, all data flows into a centralized and unified EDW, regardless of source or ownership. This model aligns with the vision of a true Enterprise Data Warehouse, where cross-domain analysis is possible and governance is centralized. It’s ideal for smaller organizations or highly integrated enterprises where all business units share data models, definitions, and KPIs.
In contrast, a multi-tenant architecture separates data warehouses by tenant, often by BU, country, or legal entity. Each tenant may have its own schema, ETL pipeline, and reporting logic. While this introduces data duplication and overhead, it improves autonomy, reduces interdependency, and reflects the reality of large, decentralized enterprises.
Today’s Technologies
These tools follow traditional data warehousing principles: structured data, schema-on-write, batch ETL, and layered architecture optimized for BI workloads using SQL over columnar storage.
Two main processing architectures exist:
- SMP (Symmetric Multi-Processing)
A single-server architecture where compute and storage share the same resources. It offers limited scalability, as there is no parallelism across multiple nodes. Example: PostgreSQL with columnar extensions. - MPP (Massively Parallel Processing)
A distributed architecture where data and compute are spread across multiple nodes working in parallel. In most MPP systems, compute and storage are tightly coupled per node, which means scaling requires adding full nodes.- On-prem (commercial): Teradata, Oracle Exadata, IBM Db2 Warehouse, Vertica
- On-prem (open/free): ClickHouse, Greenplum
- Cloud: Redshift, Azure Synapse, BigQuery, Snowflake (⚠️ some of these platforms are gradually adopting lakehouse features).
- Streaming oriented: Druid, ClickHouse, Rockset
Real-life perspective
In practice, traditional data warehousing is still found in large, risk-averse organizations, particularly in finance, insurance, and public sectors, where sensitive OLTP systems (often Oracle) remain strictly on-prem. These setups typically rely on proprietary platforms like Oracle Exadata or IBM Db2 for the analytical layer. While effective for structured reporting and regulatory compliance, they often suffer from limited scalability, expensive hardware upgrades, and vendor lock-in.
Vertical scaling (more RAM, more CPU) was the default option. But with growing volumes and data science needs, these monolithic architectures show their limits: limited integration with modern tools, vendor lock-in, poor handling of semi/unstructured data.
We haven’t addressed streaming, virtualization, ML or operational analytics, because these capabilities were not natively supported/common in traditional on-prem data warehousing technologies.
Of course, cloud-native data warehouses like Snowflake, BigQuery, Redshift, or Synapse are now widely adopted. But increasingly, they are evolving toward a Data Lakehouse paradigm, decoupling storage and compute, embracing open data formats, and enabling modern capabilities such as streaming, virtualization, and scalable machine learning directly on top of cloud data storage.
To conclude, is this architecture still relevant?
Traditional Data Warehousing remains in use today, particularly for structured data and business intelligence use cases. However, it is being adopted and promoted less frequently 📉 as it quickly shows its limitations when dealing with unstructured or semi-structured data.
This has paved the way for more modular and flexible architectures like Hybrid Data Warehousing or Data Lakehouse, which blend the structure of traditional warehouses with the scalability of data lakes.
👉 To learn more, check out the deep dive: Architectural Deep Dive: Hybrid Data Warehousing or check the global overview.