

Imagine This
I know, I know, what’s the simplest way to share a large dataset with another team?
File > Export > Export as CSV. We all do it that way 🤫 !
However, let’s consider what happens on the receiving end. When you open a plain CSV file, you have to manually convert it and select the delimiter and qualifier. If you choose the wrong settings, you might end up with a mess 🥴, a single logical row could span multiple lines due to unescaped line breaks inside the fields. You try adjusting the settings again, but it still doesn’t work (you lock your computer and go take a coffee break 😑).
So, if CSV isn’t the best choice, what about alternatives?
Human-Readable Encoding Formats
Instead of simply asking, “Which format is better?”, we need to evaluate them based on specific use cases. These formats prioritize human readability, but they often come with trade-offs in efficiency and precision.
Let’s start by exploring encoding formats commonly used for file transmission, downloads, and data sharing between teams.
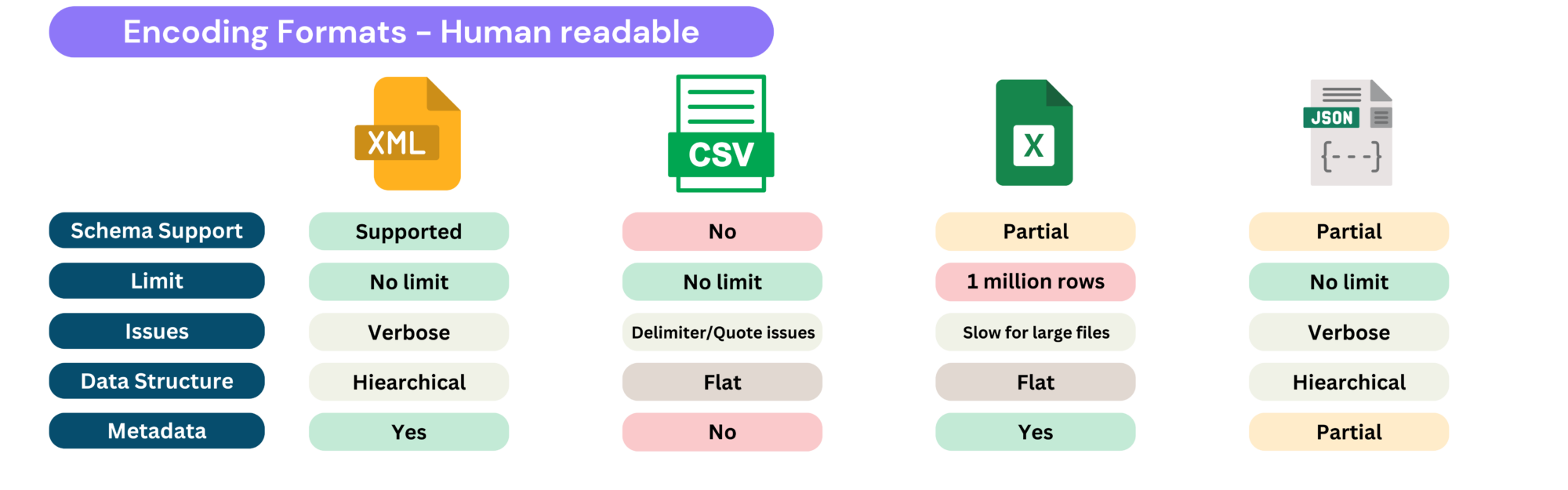
XML (which is starting to feel really outdated now…)
- Readable, supports schemas for validation.
- Verbose, cannot inherently distinguish between numbers and strings.
- Best suited for document-oriented systems and legacy applications where XML is already deeply embedded.
CSV (unlimited beast)
- Simple, widely supported, easy to generate and read, no size limit.
- Lacks a schema, does not differentiate between numbers and strings, struggles with handling commas, newlines, and qualifiers.
- Used for analysis, reporting, and data exchange between different tools, but unsuitable for structured data integration or large datasets.
Excel (the immortal tool)
- User-friendly, used for data exploration, supports rich formatting, formulas, and pivot tables.
- Limited to ~1 million rows, inefficient for large-scale data processing due to XML-based storage structure, prone to data corruption.
- Best for business reporting, financial modeling, and interactive data analysis, but not suitable for automated or large-scale data processing.
JSON (the API terminator)
If you’ve ever worked with an API or a document database like MongoDB, you’ve definitely come across JSON. It’s widely used in the industry for data exchange between services—whether on the web, in software, or across different systems :
- Readable, widely adopted, supports optional schemas.
- Verbose for large datasets, floating-point precision issues, and lacks native binary data support.
- Ideal for API responses, configuration files, and cases where human readability matters, but not suited for large-scale data transfers.
Binary Encoding Formats
Now, let’s explore other types of encoding formats!
Communication between services
If you need a faster alternative to JSON, optimized for serialization speed and compactness, these formats are built for the job! Designed specifically for service-to-service communication and efficient serialization/deserialization in applications.
Binary JSON Equivalents
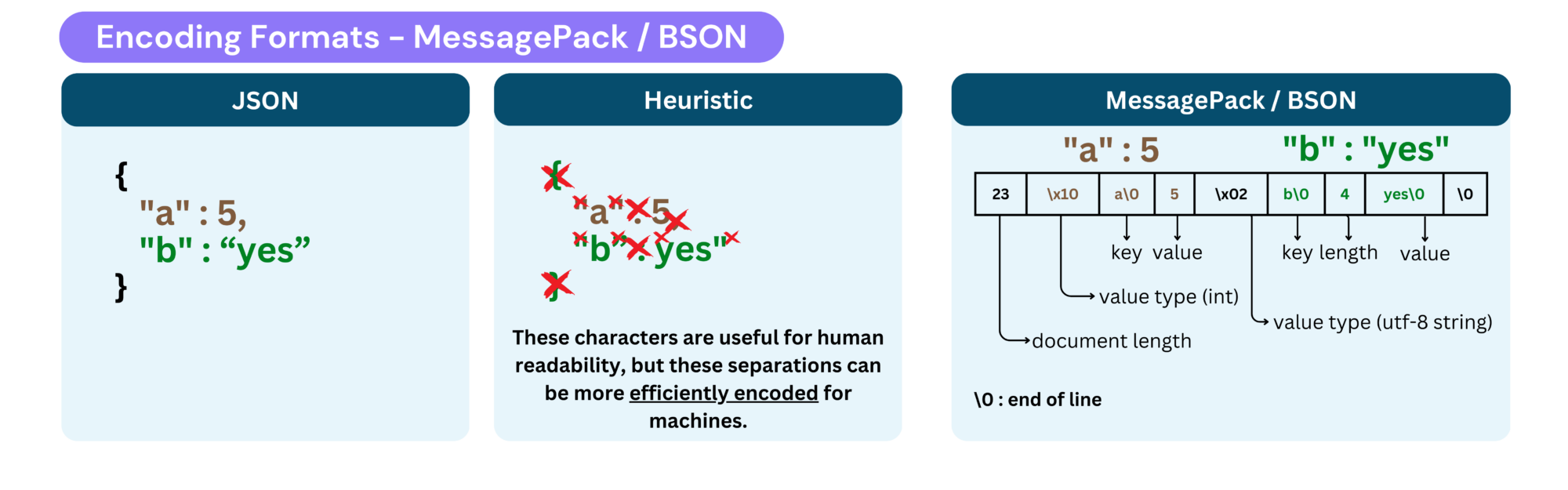
These formats serve the same purpose as JSON but in a more efficient, compact, and faster way. Instead of storing data as human-readable text, they encode it in a binary format, reducing size and improving processing speed :
- 2 technologies : MessagePack (general-purpose) and BSON (used in MongoDB)
- Removes verbose characters (
{},:,,,"), encodes object sizes and field lengths instead. - Compression gain range from ~1.2× to 2× smaller than JSON/CSV.
💡 In real-life scenarios: Suitable for lightweight data serialization in applications where JSON is used but performance is a concern. BSON is specialized storage format for MongoDB.
Thrift & Protocol Buffers (Protobuf)

These formats are highly efficient binary serialization formats designed for fast communication between services. Unlike JSON or MessagePack, these formats require a strict schema to define the structure of the data before serialization :
- Strict Schema Required : In Protobuf and Thrift, each field is assigned a unique number, which is essential for serialization and deserialization.
- Compression gain range from ~2× to 4× smaller than JSON/CSV.
- Highly efficient, schema-driven ensuring structured data, and widely used in RPC (Remote Procedure Call) systems.
💡 In real-life scenarios: Intended for internal use only, such as gRPC and microservices within the same application. Modifying field numbers can corrupt the entire dataset, making it unreadable. This encoding is designed for strict, contract-based communication between internal services.
Large datasets storage and processing
These formats are used for storing and retrieving large datasets, similar to CSV/Excel but more efficient.
Avro

A row-based format optimized for fast write and read operations. It supports schema evolution, making it suitable for streaming platforms like Apache Kafka :
- Row-based, used in Hadoop ecosystems.
- Requires a schema, but does not require field numbers.
- Compression gain range from ~2× to 5× smaller than JSON/CSV.
💡 In real-life scenarios: Avro provides significant file compression while maintaining high I/O performance, making it more efficient than CSV for large datasets.
Parquet / ORC

A columnar storage format that is highly optimized for analytics, especially in Big Data frameworks like Apache Spark, Hive, and Presto. It provides excellent compression and faster queries compared to CSV :
- Column-oriented, highly efficient for analytical workloads.
- Best for data warehousing, data lakes, and analytical applications involving large datasets.
- Allows better compression than row-based formats because columns have uniform data types.
- Alternative: ORC (Optimized Row Columnar)—also columnar, used in Hadoop for high compression.
- Compression gain range from 5× to 20× smaller than JSON/CSV.
💡 In real-life scenarios: Parquet is commonly used as an efficient format for storing files in the staging layer, for data transmission, and serves as the underlying format for Delta files.
Delta Lake (Hudi, Iceberg)
Delta Lake is an open-source storage layer that brings ACID transactions, schema enforcement, and time travel to data lakes and data lakehouses. It builds on Parquet files but adds transactional consistency, making it ideal for scalable, reliable data pipelines.
Unlike CSV or standalone Parquet, a Delta table is not a single file, it’s a directory structure that evolves over time. Each write appends new Parquet files and updates the transaction log:
- Parquet files for the actual data (columnar, compressed)
- JSON log files for tracking schema, metadata, and transactions (aka the transaction log
_delta_log/)
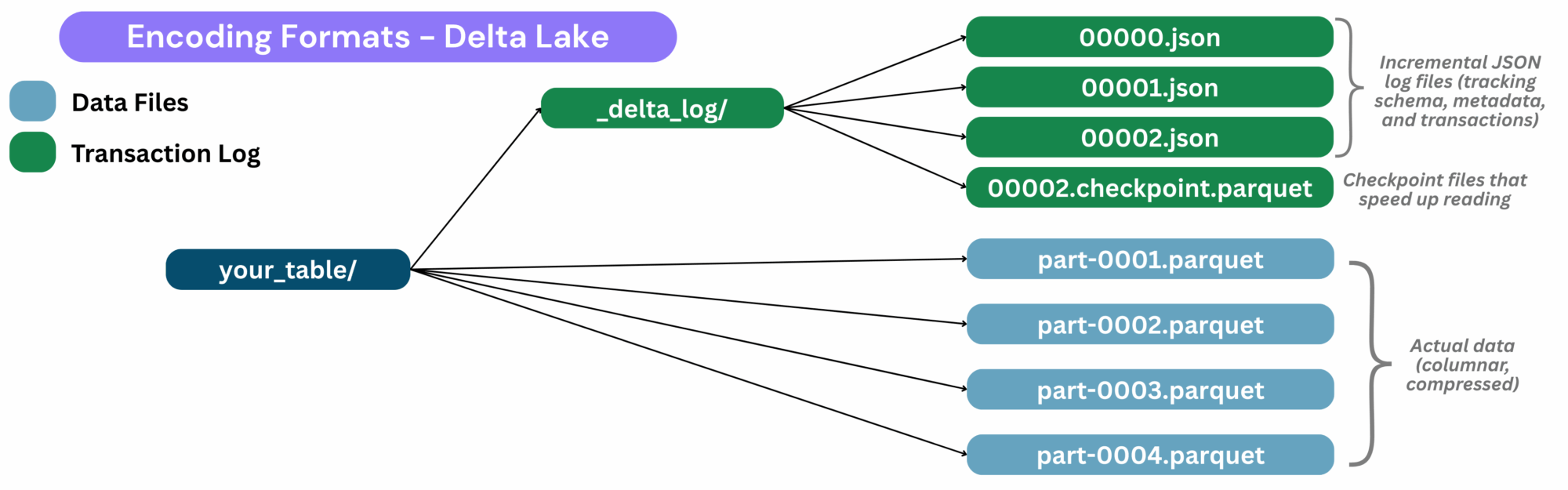
Key features:
- Supports atomic writes, updates, deletes (things CSV, JSON, or plain Parquet can’t do ‼️).
- Enables time travel (query past versions) and schema evolution.
- Works natively with Apache Spark, Databricks, and Delta-RS.
Beyond Delta Lake, two other open formats, Apache Hudi and Apache Iceberg, have emerged to solve similar problems around data reliability, updates, and large-scale analytics. All three support features like ACID transactions, schema evolution, and time travel, but they differ significantly in architecture:
- Delta Lake: Uses a simple JSON transaction log and stores data in Parquet, making it tightly integrated with Spark and Databricks.
- Hudi: Created by Uber, stores both metadata and data in Avro, and is optimized for real-time ingestion and incremental processing.
- Iceberg: Designed by Netflix, uses a manifest-based metadata model in Avro/JSON, enabling hidden partitioning, version control, and compatibility with multiple engines like Trino, Flink, and Snowflake.
Arrow
Question: JSON is the go-to format for exchanging data between operational services, but what if you need to exchange large datasets between two analytical systems ?
Answer: Apache Arrow comes in 🙋! Designed for in-memory and columnar data processing. It enables zero-copy data exchange between tools like Pandas, Spark, and DuckDB, eliminating serialization overhead. Unlike Parquet or ORC, which is optimized for disk storage, Arrow keeps data in RAM for ultra-fast analytics and real-time querying.
Summary
Oh, wait, that’s all ? What if I want a human-readable AND a well-compressed and efficient file ?
Reader question
Unfortunately, aside from slightly compressing your CSV with a tool (which doesn’t improve its efficiency), having a highly compressed and optimized file does not go hand in hand with human readability.
So yes, long live our dear CSV, Excel, and JSON files! But when we start exchanging files of several GBs or even TBs, let’s not forget to use the right format 🚨 !