

Disclaimer
This article is part of a series, we highly recommend reading the following articles:
- The Foundation of a Scalable Data Architecture : Data Modeling 101
- Data Modeling: Dive into data normalization levels
This is a difficult article 😵💫, so understanding all the previous concept is really important !
Introduction
One of the most overlooked yet important aspects of data modeling is understanding how data changes over time 🔄. Whether you’re working in a transactional system or designing an analytics platform, being explicit about data mutability helps drive better storage design, pipeline logic, and analytical accuracy !
At its core, data can be classified into two broad types based on its change behavior, either immutable or mutable. Each type has implications not only for how the data is stored, but also for how it is queried, audited, and modeled.
Types of data mutability
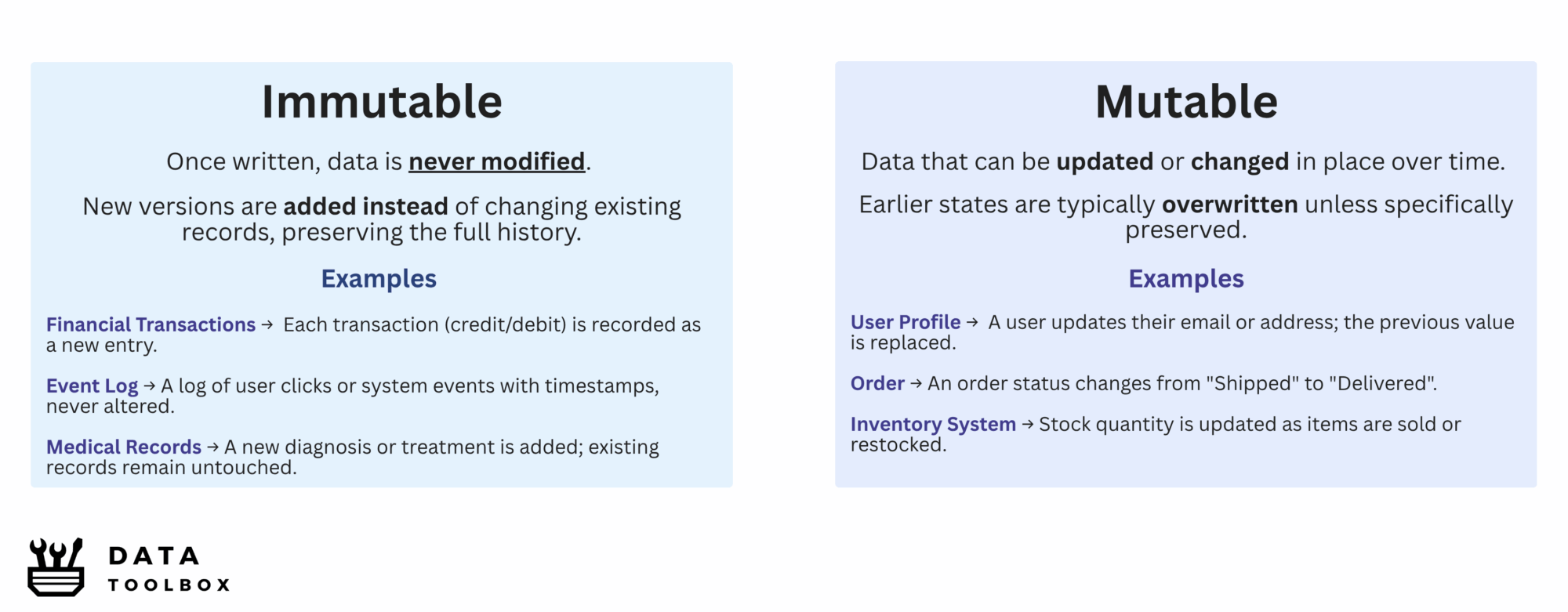
Immutable Data
Immutable data is data that, once written, is never modified ☠️. Any change to an immutable record results in a new record being added, while the old record remains untouched. Examples include append-only event logs, financial transactions, or blockchain records. In these systems, records represent facts at a point in time and are never updated or deleted after the fact.
For example, an event streaming system may maintain an immutable record of all user actions or sensor data, with each new event appended alongside a timestamp to preserve the full historical context. A similar approach is used in financial systems, where instead of modifying past records, changes are logged as new transactions, ensuring a transparent and traceable audit trail.
Mutable Data
Mutable data represents information that reflects the current state of an entity and is subject to change over time. It is stored in a way that allows values to be updated in place, meaning previous values are typically overwritten. The system always reflects the latest known value.
Examples include customer profiles, product information, or orders (with potentially changing statuses), all of which can evolve through user interactions with a system. Without applying specific modeling strategies, updates to such mutable data often overwrite previous states, leading to the loss of historical context 🗑️ and limiting the ability to perform retrospective analysis.
In transactional systems (OLTP)
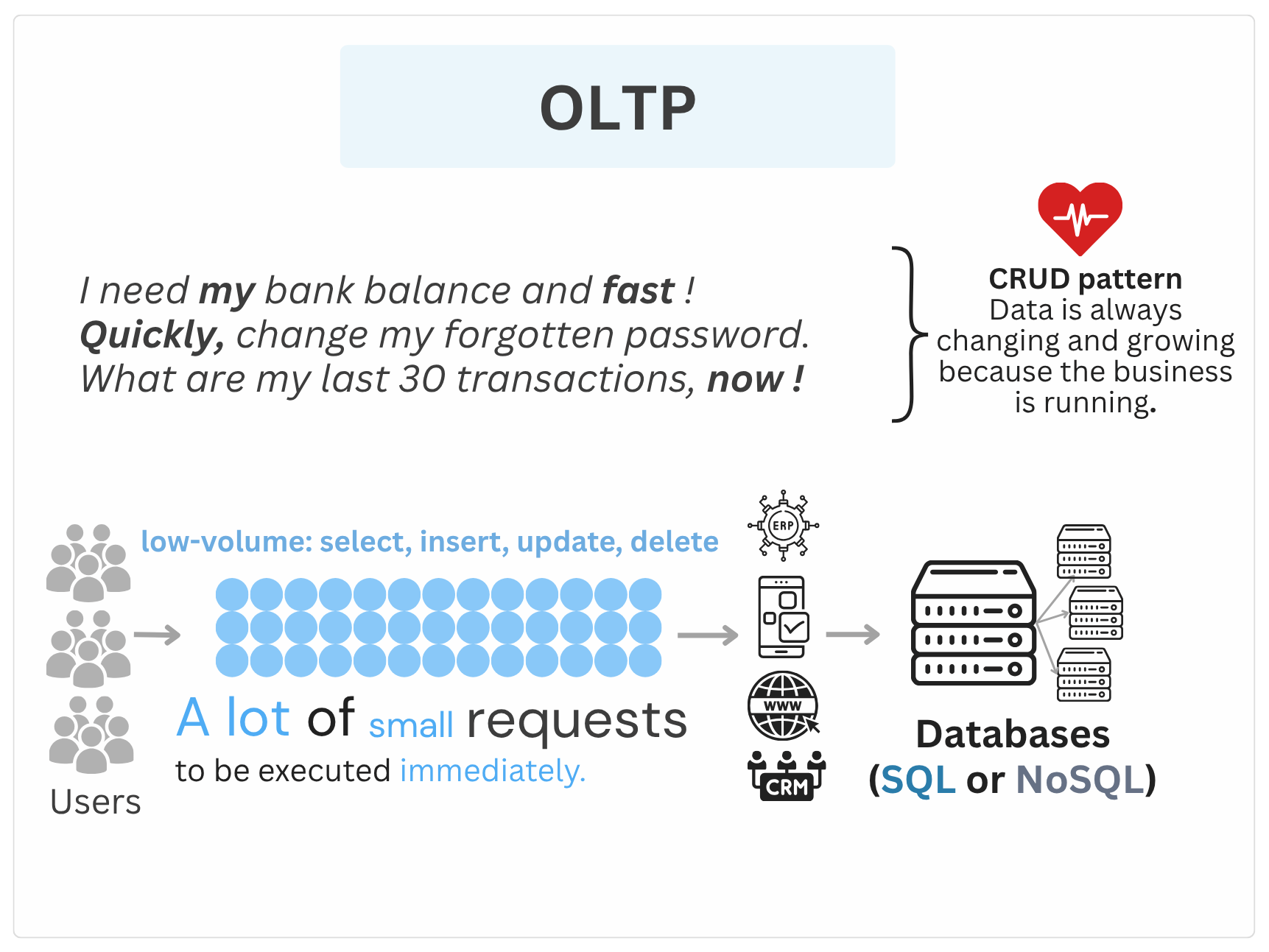
First of all OLTP systems prioritize high-speed transactional performance. Dump 🚮 all records in one table can result in inefficient indexing and reduced system performance. A best practice is to separate the current state of the data from historical or archived records.
Immutable data
1️⃣ Table characteristic
Append-only tables are the norm. Each row is stamped with an immutable unique primary key + a creation timestamp (and often a natural business key). No UPDATE/DELETE is possible, only INSERT. Usually, we limit indexing to the primary key to keep the write-ahead log simple and efficient.
2️⃣ Historization strategies
The table is the history ! Every row already holds a timestamped snapshot that never changes, so you don’t need extra columns to track updates. When new events occur, you just add another row, and the complete history remains intact.
3️⃣ Optimization and Storage
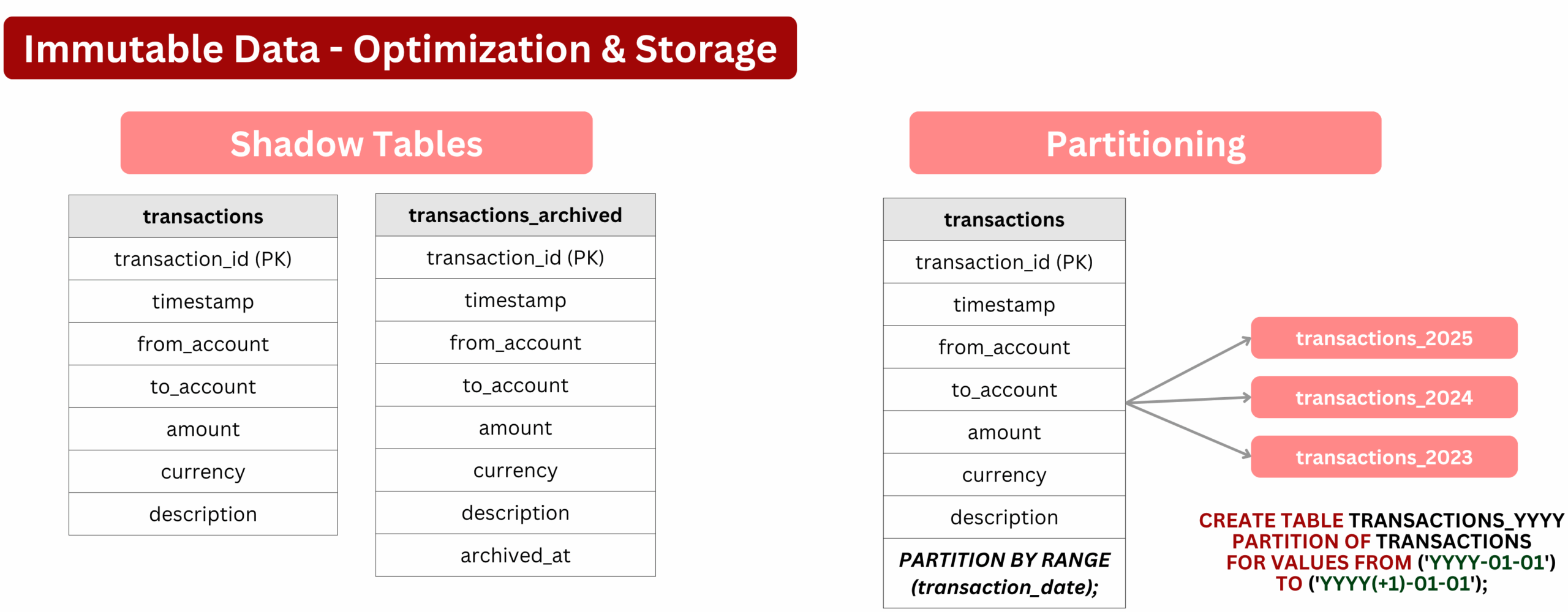
However, allowing these tables to grow indefinitely, with millions of rows and no optimization strategy, this quickly becomes unsustainable. That’s why we often turn to archiving or partitioning strategies to keep systems efficient and maintainable :
- Shadow Tables : A business rule might define that only the last 10 years of data are kept in the main tables. Older records are moved to a secondary table (like
transactions_archived), keeping the primary table lean for better read/write performance and smaller indexes. - Partitioning : Instead of storing all records in one large table, data can be split into partitions, such as by year or month (
transactions_2025,transactions_2024). This approach reduces the volume of data scanned during queries, improving indexing and performance on large datasets.
4️⃣ Deletion
Deletions are generally forbidden 🚫 ! Regulatory or business requirements can demand that every fact remain queryable forever (whatever it live or archived). Where legal obligations apply (like GDPR), deletion is usually accomplished by anonymising or hashing personal fields while preserving the row itself, thereby maintaining the audit trail.
For mutable Data
1️⃣ Table characteristic
Mutable data is typically stored in modifiable tables, where rows and attributes can be updated or changed over time. Those tables should be built for speed: one row per entity, always reflecting the latest state. Use a single stable primary key (auto-incremental for example), keep only the columns you truly need, and index the primary key and the fields you query most often. The goal is instant look-ups and lightning-fast updates, let another layer worry about history !
2️⃣ Historization strategies
Mutable data needs explicit historization, or the past is lost. That’s why the decision to treat something as mutable vs immutable has enormous design consequences. Let’s see what the most commonly used techniques are to track changes in mutable data :
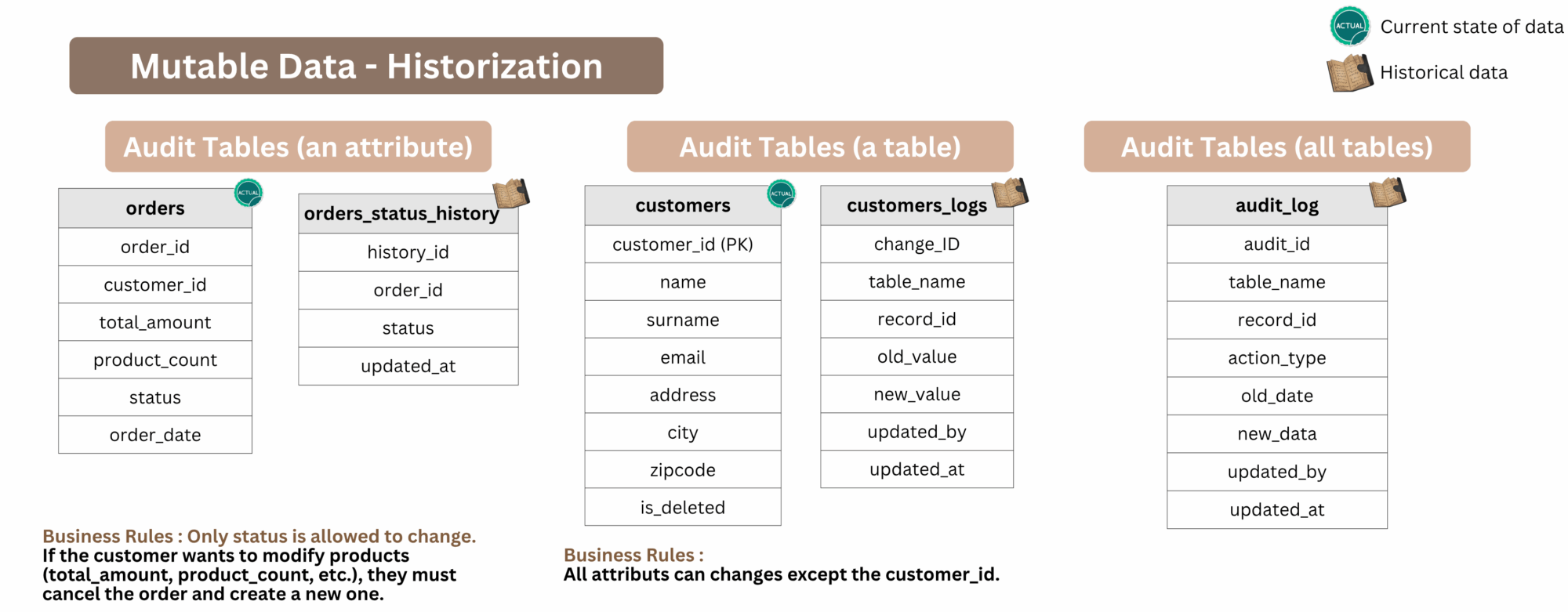
Audit tables are one of the most known ways to preserve the history of changes. A separate table tracks each UPDATE, DELETE, or INSERT, enabling reconstruction of past states. These audit mechanisms can be applied at three levels:
- Attribute-level: Track changes for a specific column (order status, etc.).
- Table-level: Log changes made to any field within a specific table.
- Database-level (rare): A centralized audit table logs changes across all tables.
In addition to audit logs, several other techniques can be used to maintain historical data in OLTP systems:

- Event Sourcing: Instead of storing the current state, every change is recorded as a discrete event (e.g.,
CUSTOMER_REGISTERED,EMAIL_UPDATED,ORDER_CANCELLED). The current state is then derived by replaying this sequence of events. This method treats otherwise mutable data as immutable and enables full traceability of how a particular state evolved. - Versioning: Creating a new version of a row with each update. A column such as
is_currentwithversion_idindicates the active record, while older versions remain in the same table. This strategy simplifies historical tracking without the need to replay events and strikes a practical balance between implementation simplicity and historical completeness. - Temporal Tables: Supported by databases like PostgreSQL or Oracle. They allow automatic tracking of row-level changes over time without requiring manual intervention. By defining a system time period, typically using
valid_fromandvalid_tocolumns, the database maintains a complete history of modifications. EnablingSYSTEM_VERSIONINGensures that each change is captured and stored seamlessly.
3️⃣ Optimization and Storage
When soft-deleted or outdated rows (versioning) pile up, the table gets bloated and slows down. Regularly move these inactive versions out to keep the main table light using same shadow tables 👻 as for immutable data.
4️⃣ Deletion
For deletions, soft deletes are preferred to preserve foreign key integrity. Force deletes are typically avoided. For GDPR compliance, Personally Identifiable Information (PII) fields are often anonymized instead of deleting records.
Historization in NoSQL systems
Historization in NoSQL systems
Document Stores: Capable of both mutable and immutable historization. Mutable data can keep earlier versions inside the same document or in a companion change-tracking collection. For an immutable approach, each update is stored as a new document linked by a shared document or version ID.
Key-Value Stores: Redis and similar cache-oriented engines typically overwrite values and offer no durable history. In durable key-value systems like DynamoDB, you can emulate historization by writing each version under a timestamped key, but this is rarely used for long-term retention.
Wide-Column Stores: Naturally suited to append-only, immutable designs: every update is written as a new row keyed by a timestamp, enabling efficient historical queries.
Graph Databases: Changes are recorded through temporal nodes or edges that include validity intervals (valid_from, valid_to) or a version metadata. This lets you reconstruct the graph at any point in time while preserving both mutable updates and immutable history.
In analytical systems (OLAP)
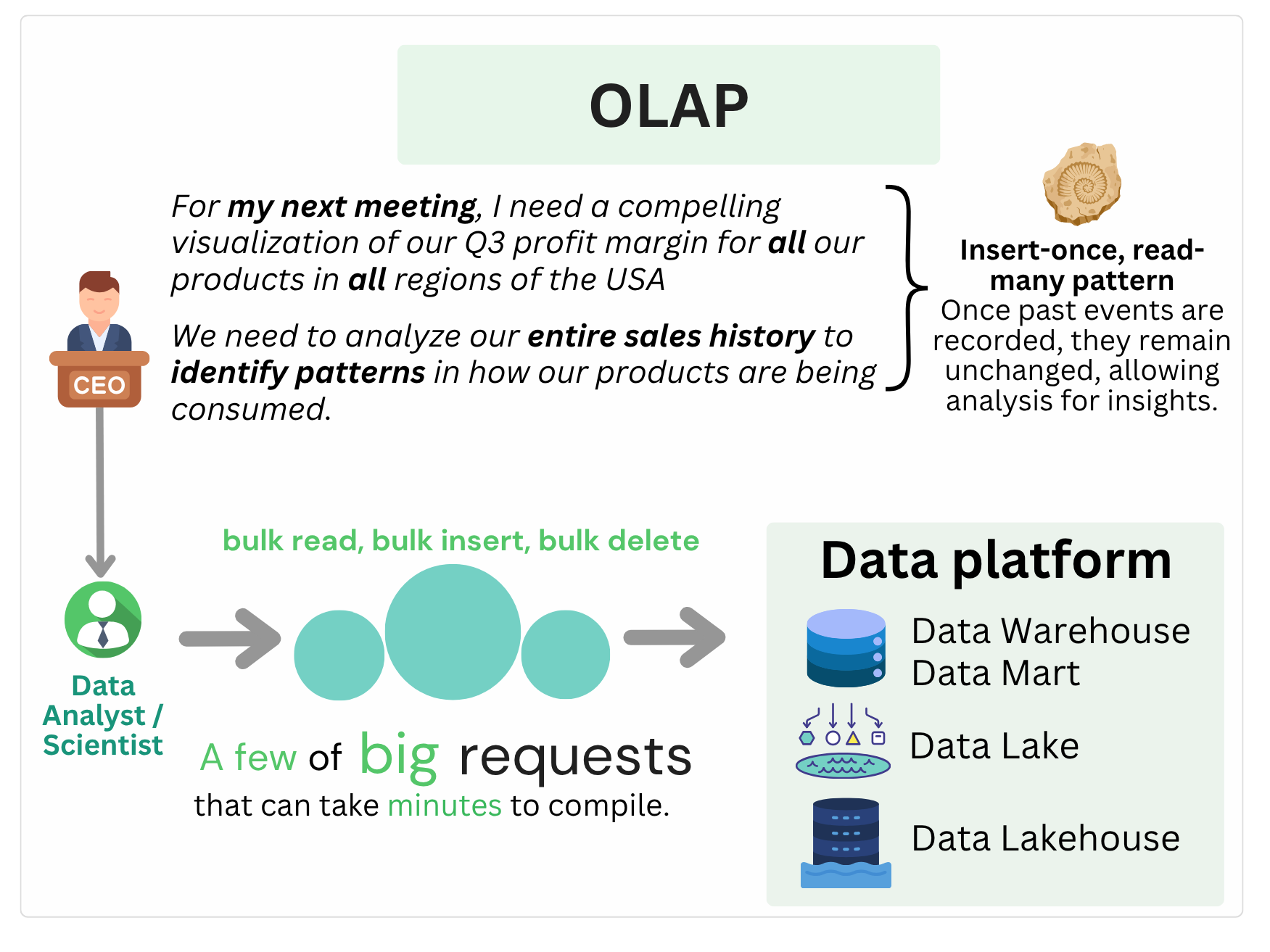
In OLAP systems, the goal is not to reflect the current state of the world in real-time, but to analyze how things have changed over time, and to support complex aggregations, trend analysis, and data exploration at scale 📈.
These systems are designed to handle large volumes of data, often coming from many different sources : operational databases, logs, semi-structured data, APIs and transformed into formats optimized for querying. Because analytical needs prioritize completeness, consistency, and historical accuracy, the way data mutability is handled in OLAP is different from OLTP.
Immutable Data
1️⃣ Table characteristic
Immutable data is stored in append-only tables, similar to OLTP systems. These tables can be populated either row by row via streaming, or through batch processes such as full loads or incremental loads at regular intervals. The primary goal is to ensure auditability, reproducibility, and to simplify data analysis.
These tables are typically found in the Bronze Layer (ingestion), in the Silver Layer, they are cleaned, enriched, and made historically complete; and in the Gold Layer (data marts), they serve as fact tables optimized for analytics.
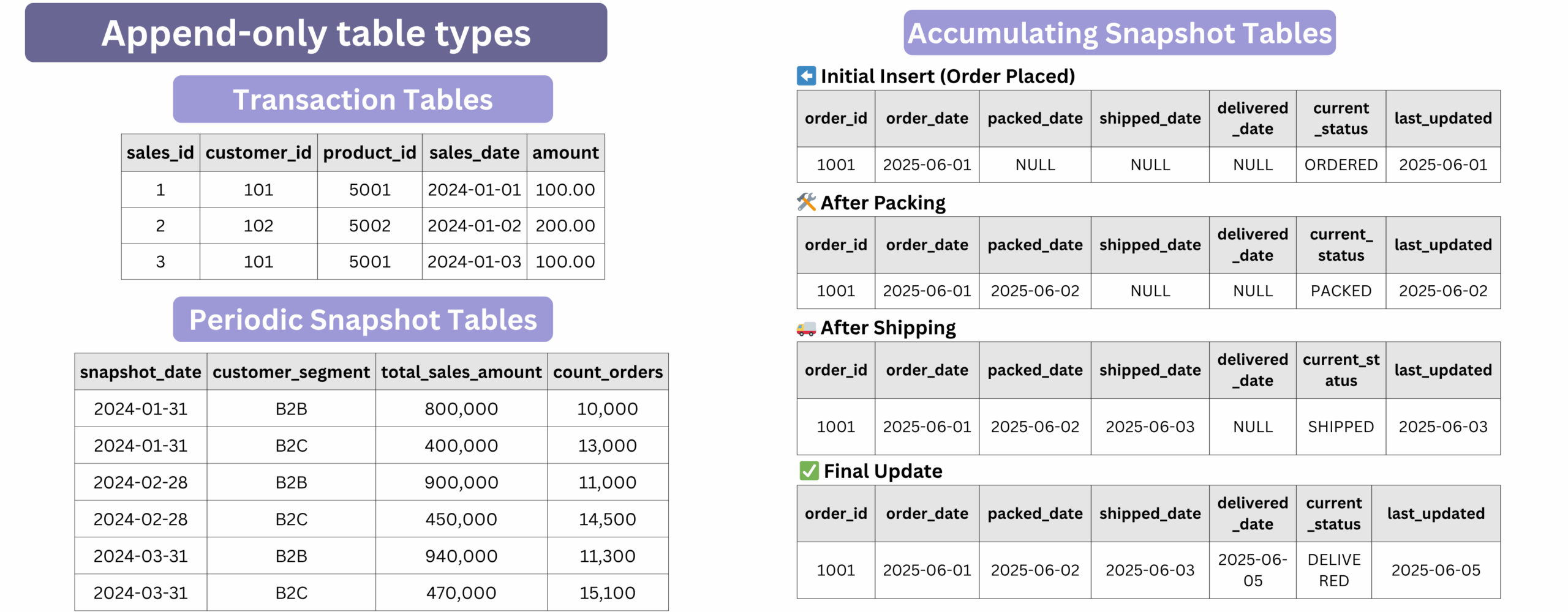
Those append-only tables come in different types, each suited to specific use cases:
- Transaction Tables: one row = one atomic transaction, like a payment, a purchase, a login, or a price change.
Use this for raw, detailed data that captures what happened, when, and by whom. The system just appends new transactions, they are no updates, no deletes.
- Periodic Snapshot Tables: one row = a full picture taken at regular intervals (daily stock, hourly balance, monthly inventory, etc.).
Use this when you need totals or states at specific points in time that can’t be rebuilt from raw transactions. Each snapshot writes a new file—purely append-only.
- Accumulating Snapshot Tables (rarely used): one row = the full lifecycle of a process (like ordered → confirmed → shipped → delivered).
Use this when you want a record that updates over time.It starts with a blank row, then updates it step-by-step using versioned, atomic file rewrites.
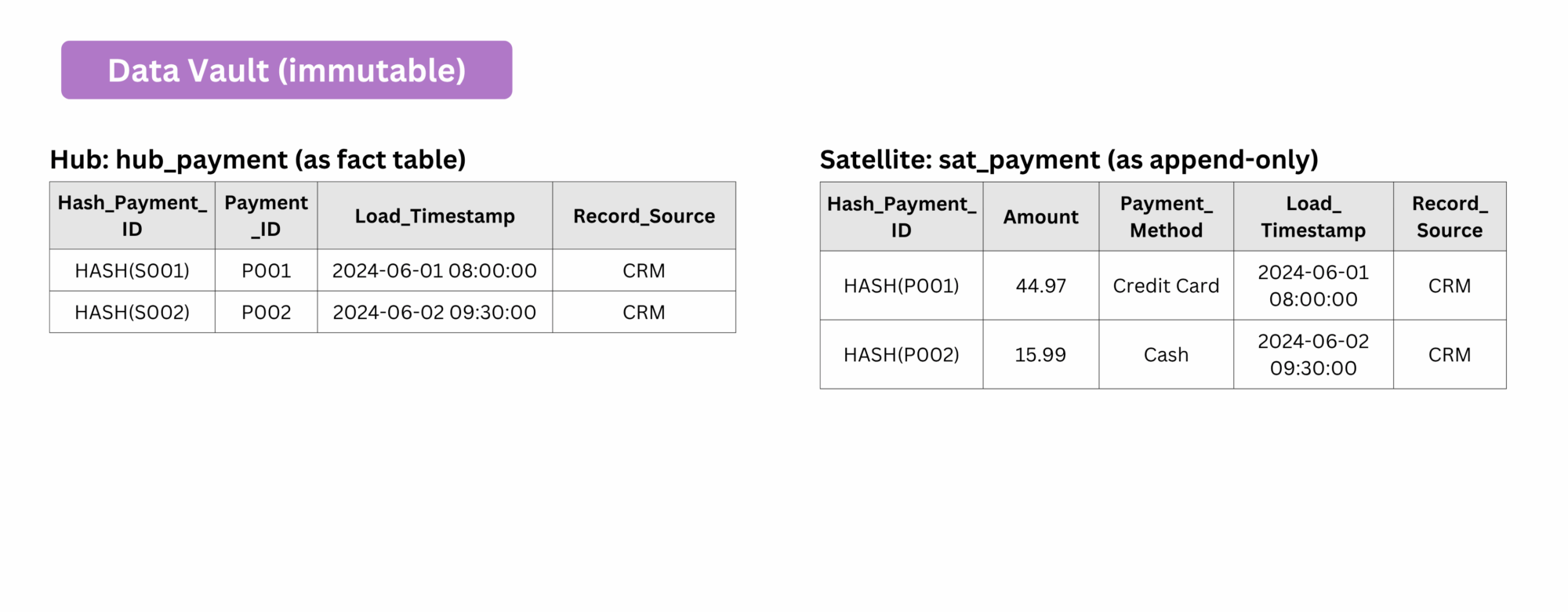
There’s also the Data Vault approach (explained here), often used in the Silver layer, which naturally supports append-only modeling. It’s designed to retain historical states by default, making historical tracking an inherent part of the model.
2️⃣ Historization strategies
Immutable modeling in OLAP ensures that historical data is preserved by design. However, immutable does not mean indiscriminate ingestion.
You must define clear strategies for historization to avoid uncontrolled data growth and ensure analytical relevance:
- Transaction Tables / Data Vault: Define the temporal scope. Are you analyzing the last 2 years of activity, or the full 10-year archive ? Apply retention policy accordingly.
- Periodic Snapshots: Choose an appropriate snapshot cadence (hourly, daily, weekly) based on the volatility of the data and the resolution required for analysis.
- For all append-only tables: Determine the right level of detail. Do you store every inventory item by each SKU, or aggregate by product category ?
3️⃣ Optimization and Storage
Since data is immutable and grows endlessly, optimization is crucial:
- Partitioning: Partition by time (day/month/year) or logical buckets (customer segment, region). This reduces scan time and improves query performance.
- Clustering: Within each partition, sort rows by frequently filtered columns (
user_id,product_id) to maximize data skipping. - Compaction (for Lakehouse): Merge small files into larger ones to reduce metadata overhead and improve I/O performance.
- Vaccum (for Lakehouse): Some storages formats (like Delta, Iceberg or Hudi) support time-travel queries and schema evolution, but make sure you vaccum the old files to keep the performance running.
4️⃣ Deletion
In immutable OLAP systems, deletions are not handled by modifying existing records. Instead, systems preserve history and apply one of the following strategies:
- Append a tombstone record: Instead of deleting, add a new row marking the entity as deleted (
status = 'deleted'or aneffective_totimestamp). - Anonymize sensitive fields: For compliance, Personally Identifiable Information (PII) is overwritten via an append-only update or replaced in a new version of the dataset.
Deletion, in OLAP, is really about versioning, not erasure, maintaining a full audit trail while optimizing storage over time.
Mutable Data
1️⃣ Table characteristic
Mutable data in OLAP systems can be stored in either append-only tables or modifiable tables that support update and delete operations through mechanisms like MERGE. In the Ingestion Layer, data is typically ingested in an append-friendly manner, via event streams or periodic batch snapshots, to capture raw changes with full traceability.
As data progresses through the pipeline, particularly in the Silver and Gold Layers, it is often transformed, merged, or updated to apply business logic, reflect the current state, or support historical reconstruction.
2️⃣ Historization strategies
Periodic snapshots and Change-aware snapshots
Periodic snapshots capture the full state of a table at regular intervals (daily, weekly, etc.). This batch approach is simple and widely used, especially in bronze layers, but can lead to redundancy when most records remain unchanged.
Change-aware snapshots include only records that have changed since the last capture time. This reduces duplication and storage, but introduces ambiguity: if a record disappears, it’s unclear whether it was deleted or simply unchanged, which can complicate historical interpretation.
This strategy is often used in the bronze layer / ingestion to keep all the history saved.
Slowly Changing Dimensions (SCDs)
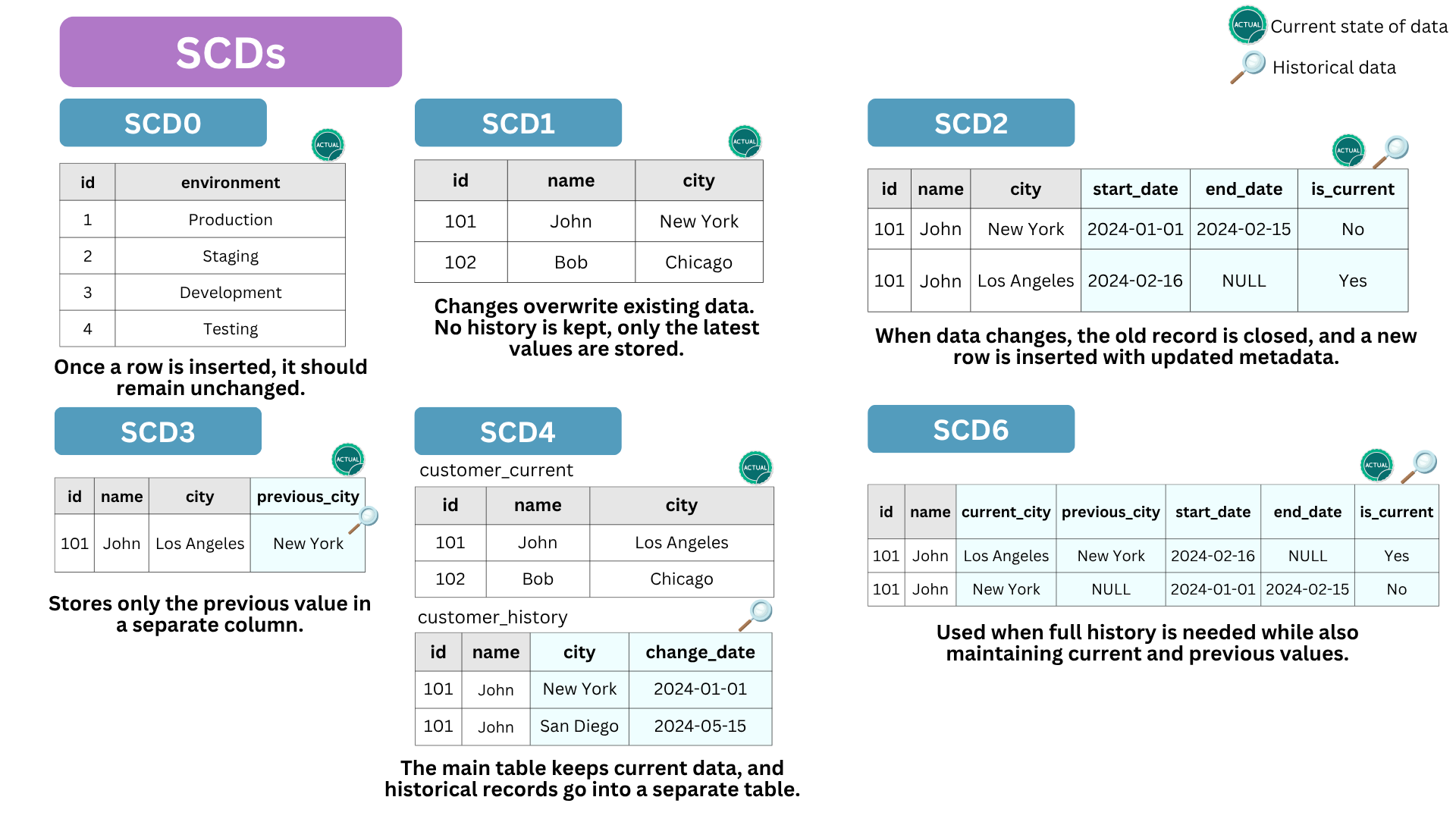
Slowly Changing Dimensions (SCDs) were introduced by Ralph Kimball in The Data Warehouse Toolkit, a foundational book on dimensional modeling. They provide structured methods for tracking changes in mutable data over time, helping maintain historical accuracy and consistency in analytical reporting.
- SCD Type 0: Once inserted, no changes in data allowed while adding row is permitted. Think of a parameter table (static data).
- SCD Type 1: Overwrites old values, retaining only the latest state (no history maintained). Only one current row remains per
ID; - SCD Type 2: Stores history using
start_date,end_date, and versioning to track changes over time. It’s the most used strategy in the industry 🔥. - SCD Type 3: Maintains limited historical changes using an additional column (
previous_value). - SCD Type 4: Moves historical data to a separate historical table.
- SCD Type 6: A hybrid approach combining types 1, 2, and 3 for comprehensive tracking.
customer table) when historical tracking is required.💡 Industry tip : To retrieve historical context from an SCD2 table, you typically join it with a fact table using the business key and a range condition on the event date. If you need to analyze the state of the dimension over time like identifying which products were active at the end of each month, you can use a date dimension to perform a temporal join and generate snapshots across time.Data Vault
Apart from SCDs, Data Vault can also be used to store mutable data because it inherently supports historical tracking by treating mutable data as if it were immutable. Changes are never overwritten ! Instead, new records are inserted with timestamps to preserve the full history.
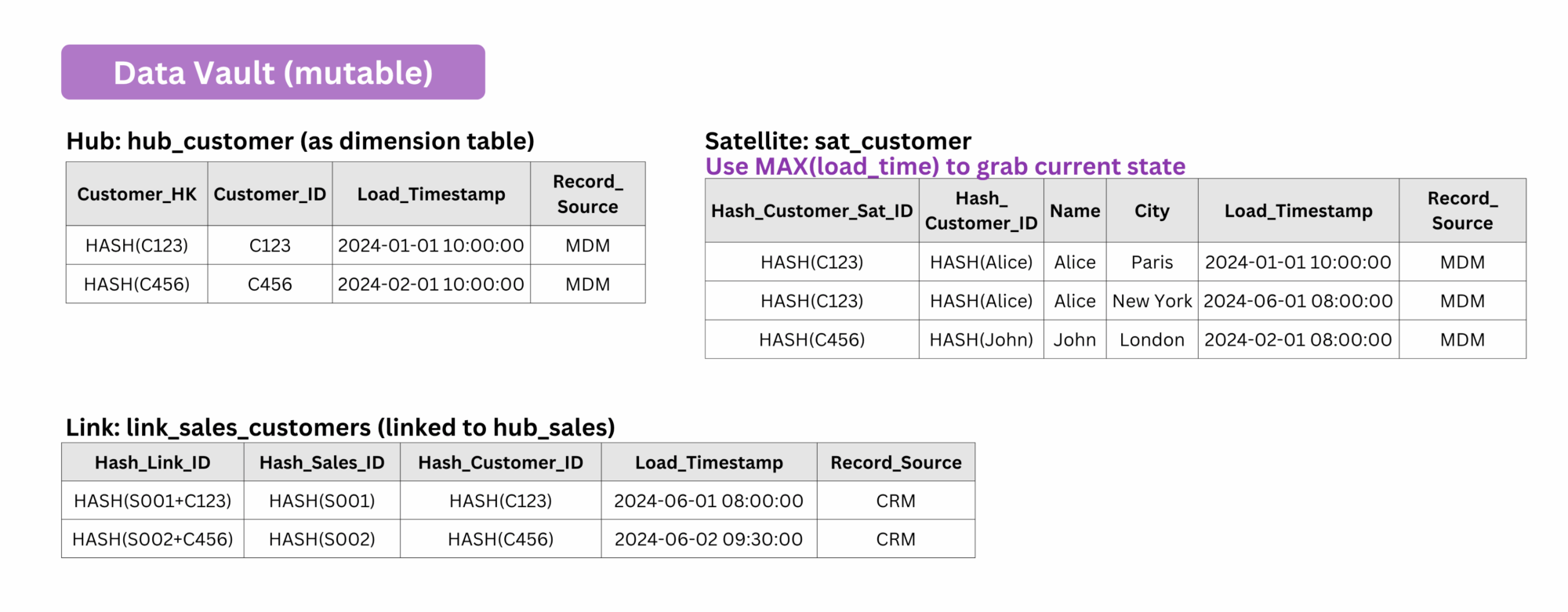
3️⃣ Optimization and Storage
You can apply the same optimization strategies as in the Immutable Data section: partitioning, clustering, compaction, and vacuuming all remain relevant.
4️⃣ Deletion
Use the same deletion strategies as described for immutable data: tombstone records, temporal versioning, and anonymization.
When required, physical deletion can be managed via retention policies and vacuuming, while preserving auditability.
Conclusion

Yeah, because I’m not haha… This was one of the most difficult articles to write, data modelization is a hell 🔥.
Like, everyone wants to do AI without math, and everyone wants to do data without modeling !
But I think this paper, which à peu près sums it all up, will be your bible 📖, the one you’ll come back to again and again whenever you’ve got questions to answer.