

Disclaimer
This article is part of a series, we highly recommend reading the following articles:
- Analytical vs Transactional : Why You Can’t Mix Oil and Water
- The Foundation of a Scalable Data Architecture : Data Storage
These will provide the necessary context to fully grasp the concepts we discuss here.
Imagine This
Imagine you are a data engineer managing a data platform that integrates with IT systems across 10 different countries, each handling approximately 2 million clients.
Every day, your data lake ingests 20 million client records (2 x 10 countries). If you store all these records, you will accumulate around 7.3 billion records per year for one table ! (and Jeff Bezos will definitely love charging you for that 🤑).
We can all agree that this is not the best approach. While retaining historical information is crucial for analytics, the key is to implement efficient historization techniques that minimize redundancy while ensuring data integrity and accessibility.
Key Concepts in Historical Data Management
To efficiently store and retrieve historical data, it’s essential to understand the type of data being stored:
- Immutable Data : Some records, once created, should never change. These datasets are inherently append-only, ensuring data integrity and reliability.
Examples: financial transactions (e.g., invoices, payments), event logs (e.g., system logs, telemetry data), etc.
- Mutable Data: Certain records evolve over time, requiring versioning or historization techniques to maintain past and current states.
Examples: customer profiles (e.g., address, email, preferences), product information (e.g., pricing, specifications), etc.
There is also static data, which are by definition static 😅, so not in the scope of our historization article.
OLTP Historization Strategies
OLTP systems prioritize high-speed transactional performance. Retaining all historical records in a single table can lead to inefficient indexing and performance degradation. The best practice is to separate current and historical data.
Common strategies for preserving historization include :
Strategies for Immutable Data in OLTP
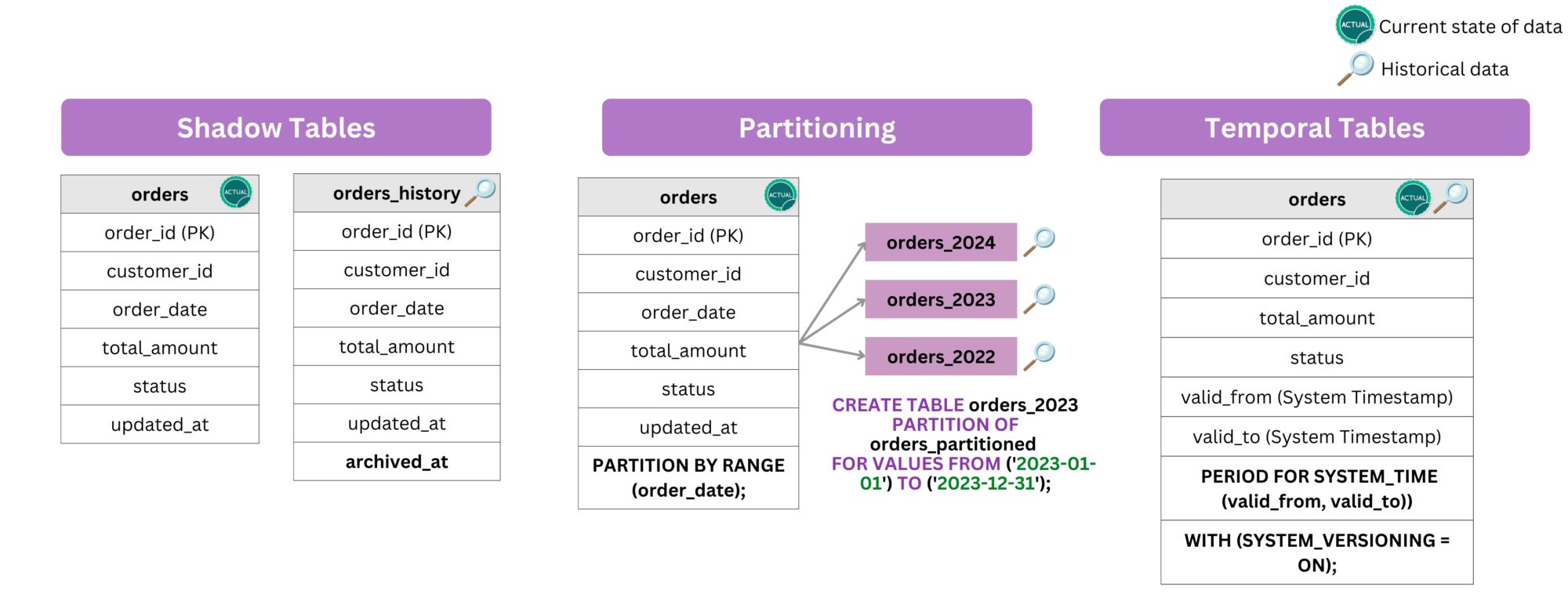
- Shadow Tables: A secondary historical table (
orders_history) stores older records, keeping the main table lean 🏃. - Partitioning: Splitting tables by year/month, e.g.,
orders_2023,orders_2024, helps in managing large datasets efficiently. - Temporal Tables: Some databases (e.g., SQL Server, PostgreSQL) support built-in system-versioned tables that automatically track historical versions of rows.
Strategies for Mutable Data in OLTP
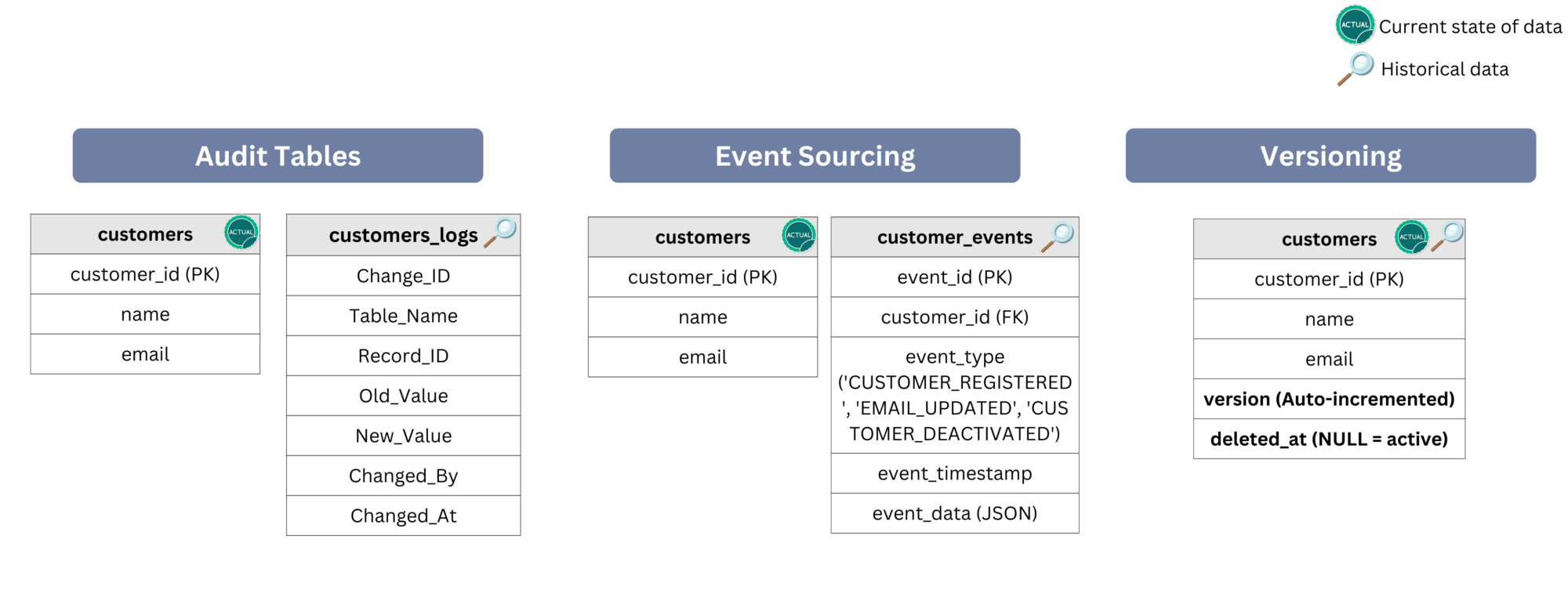
- Audit Tables (Change Logs): A separate table (
customers_logs) records every update, delete, or insert, allowing reconstruction of past states. - Event Sourcing: To make mutable data behave like immutable, changes can be stored as events, and state is derived from event history.
- Versioning with Soft Deletes: Instead of physically deleting rows, a
deleted_attimestamp marks them as inactive while preserving history with aversionstamp.
⚠️ This list is focused on SQL and relational databases, but it’s not the end of the story, click here to see others strategies about NoSQL databases.
Historization in NoSQL systems
Historization in NoSQL Systems
- Document Stores: Use document versioning (storing previous versions within the document) or change tracking collections to log updates.
- Key-Value Stores: Implement append-only updates (store versions with timestamped keys) or use TTL-based snapshots to retain historical states.
- Wide-Column Stores: Store history in time-series columns (row per update with timestamps) or immutable log tables for historical queries.
- Graph Databases: Model changes using temporal edges/nodes, where relationships store validity periods or historical versions of entities.
OLAP Historization Strategies
In OLAP (Online Analytical Processing) systems, historization focuses on maintaining historical integrity for reporting and analysis.
Strategies for Immutable Data in OLAP
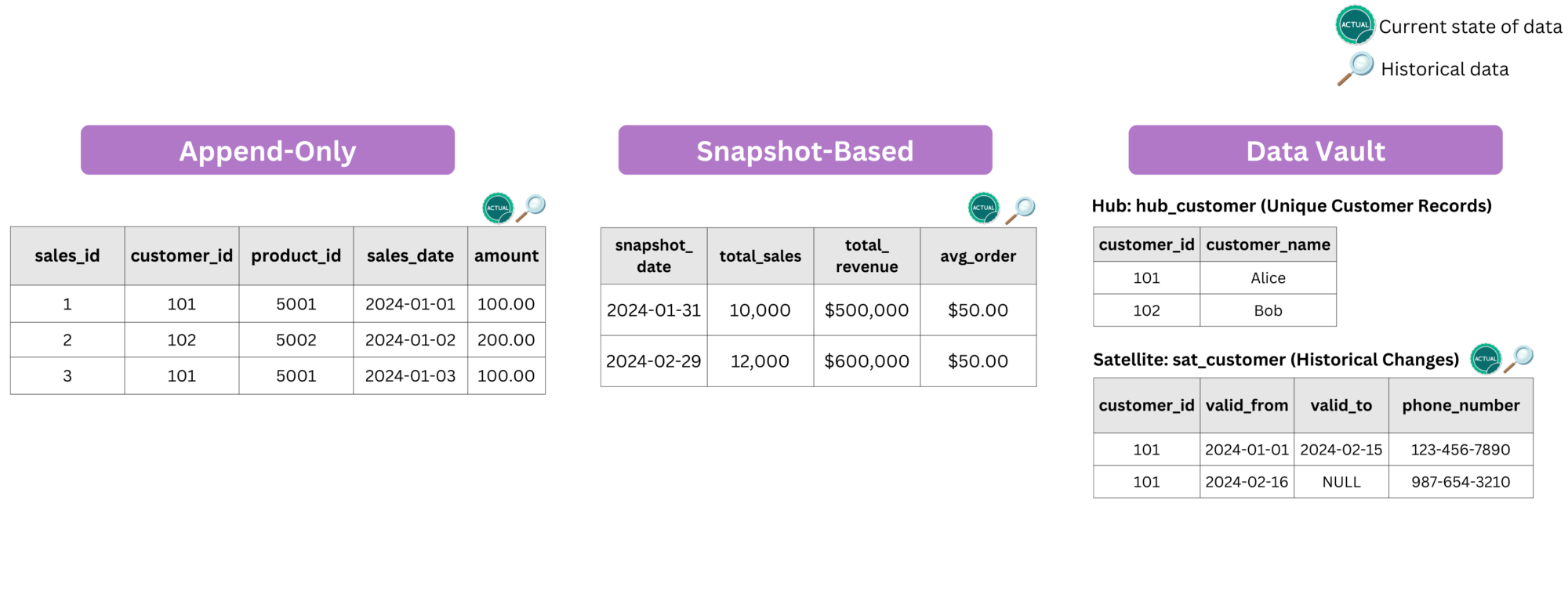
For immutable data, historical tracking is handled in an append-only manner:
- Transaction-based tables: Fact tables in gold layer or tables in silver layer with immutable data follow an append-only approach. There is no need for additional tracking mechanisms, as all historical data is naturally retained within a single table.
- Periodic snapshots: Also an append-only pattern, it stores the periodically captures complete snapshots of data at predefined intervals. This method is useful for aggregated historical tracking in gold layer or in the normalized layer where data needs versioning. For example, tracking monthly sales KPIs, where each snapshot stores values from the last day of the month (e.g., 31/X).
- Data Vault Model: This approach inherently supports historical tracking by maintaining historical states as a built-in feature.
Strategies for Mutable Data in OLAP
Periodic snapshots and Change-aware snapshots
The most dumb manner to store data for mutable data in OLAP is to use periodic snapshots just like for immutable data. You take a full photo of the table at every cut-off and dump it into a new partition. It works great when the data itself never changes, think monthly sales KPIs, where the number for April is fixed forever, but it feels wasteful when the subject is customers, addresses, or anything that changes only occasionally, because you end up cloning thousands of identical lines that haven’t changed. Still, periodic snapshots do have their upsides: they give you a simple, frozen “as-of” copy every period, are dead-simple to implement and audit, and when storage is cheap, they can be all you need !
Slowly Changing Dimensions (SCDs)
Slowly Changing Dimensions (SCDs) is a concept introduced by Ralph Kimball in his book The Data Warehouse Toolkit. This book, a foundational guide on dimensional modeling, outlines techniques for tracking changes in mutable data over time. SCDs help maintain historical accuracy in dimension tables, ensuring consistency in analytical reporting.
Different types of SCDs address varying historization needs:
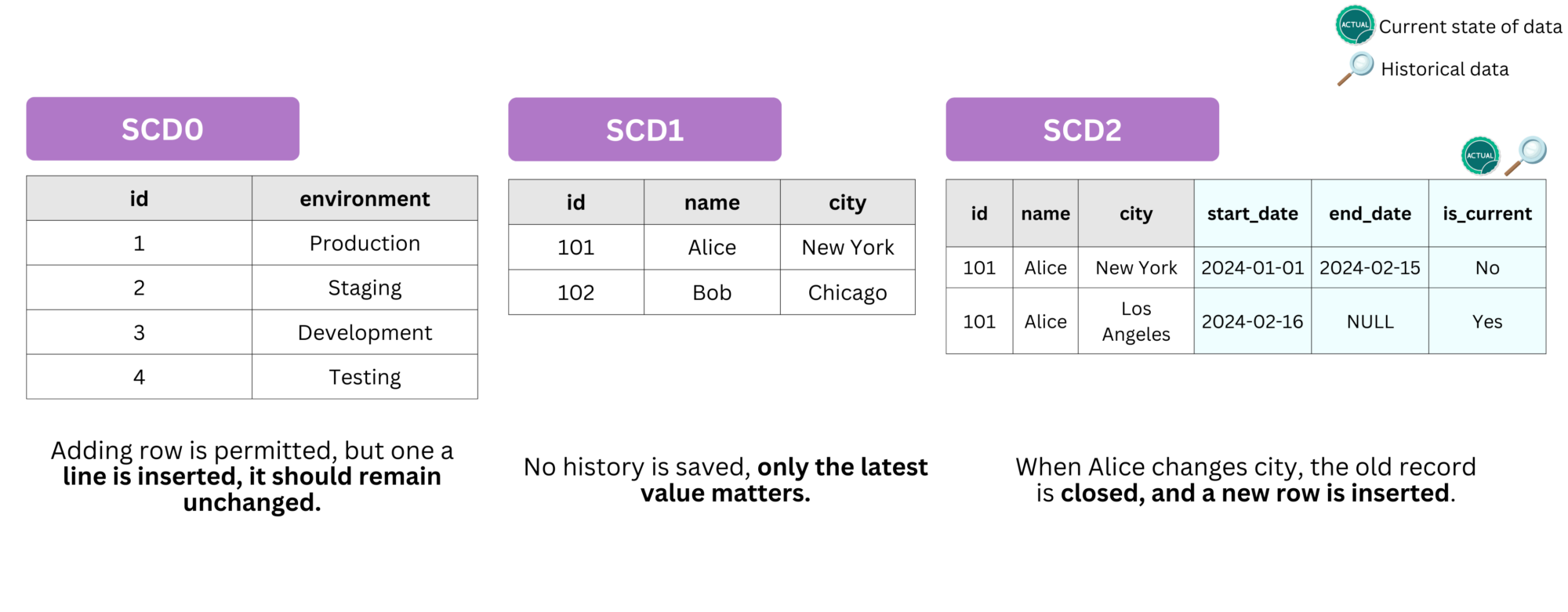
- SCD Type 0: Once inserted, no changes in data allowed while adding row is permitted. Think of a parameter table (static data).
- SCD Type 1: Overwrites old values, retaining only the latest state (no history maintained). Only one current row remains per
ID; - SCD Type 2: Stores history using
start_date,end_date, and versioning to track changes over time. It’s the most used strategy in the industry 🔥.
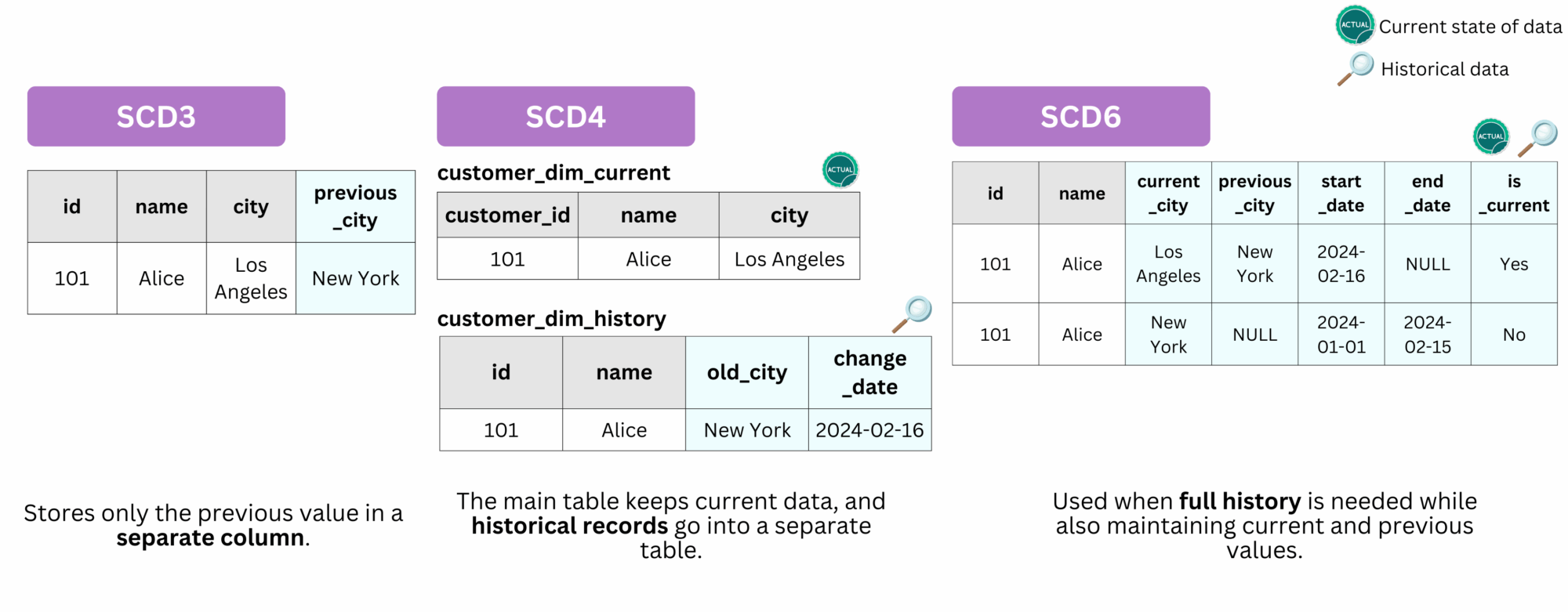
- SCD Type 3: Maintains limited historical changes using an additional column (
previous_value). - SCD Type 4: Moves historical data to a separate historical table (like OLTP shadow tables).
- SCD Type 6: A hybrid approach combining Types 1, 2, and 3 for comprehensive tracking.
💡 Industry tip : To retrieve historical context from an SCD2 table, you typically join it with a fact table using the business key and a range condition on the event date. If you need to analyze the state of the dimension over time like identifying which products were active at the end of each month, you can use a date dimension to perform a temporal join and generate snapshots across time.customer table) when historical tracking is required.Data Vault
Apart from SCDs, Data Vault can also be used to store mutable data because it inherently supports historical tracking by treating mutable data as if it were immutable. Changes are never overwritten ! Instead, new records are inserted with timestamps to preserve the full history.

Summary
And that wraps up our series on data modeling! Throughout these articles, we’ve covered a lot Normalization, Denormalization, Dimensional Modeling, Data Vault, Wide Tables, and now, how to track historical data efficiently while keeping a current state when needed. Hope you found it useful 🚀!