

Imagine This
You’re designing the next big e-commerce platform, and everything looks great ! until your database starts slowing down 🐌… Orders take too long to process, customers are complaining about delays, and your analytics dashboard crashes every time someone queries sales data from last year.
You realize that your data model might be the problem. But wait ✋! What even is a data model ? and why does choosing the wrong one feel like setting a time bomb in your system.
How It Works
At its core, a data model defines how data is stored, organized, and retrieved. Different models exist to optimize for different workloads, transactions, analytics, real-time queries, relationships, or flexible structures. Each type of these data models serves a specific use case; they are not “one size fits all 👕“.
Let’s break them down:
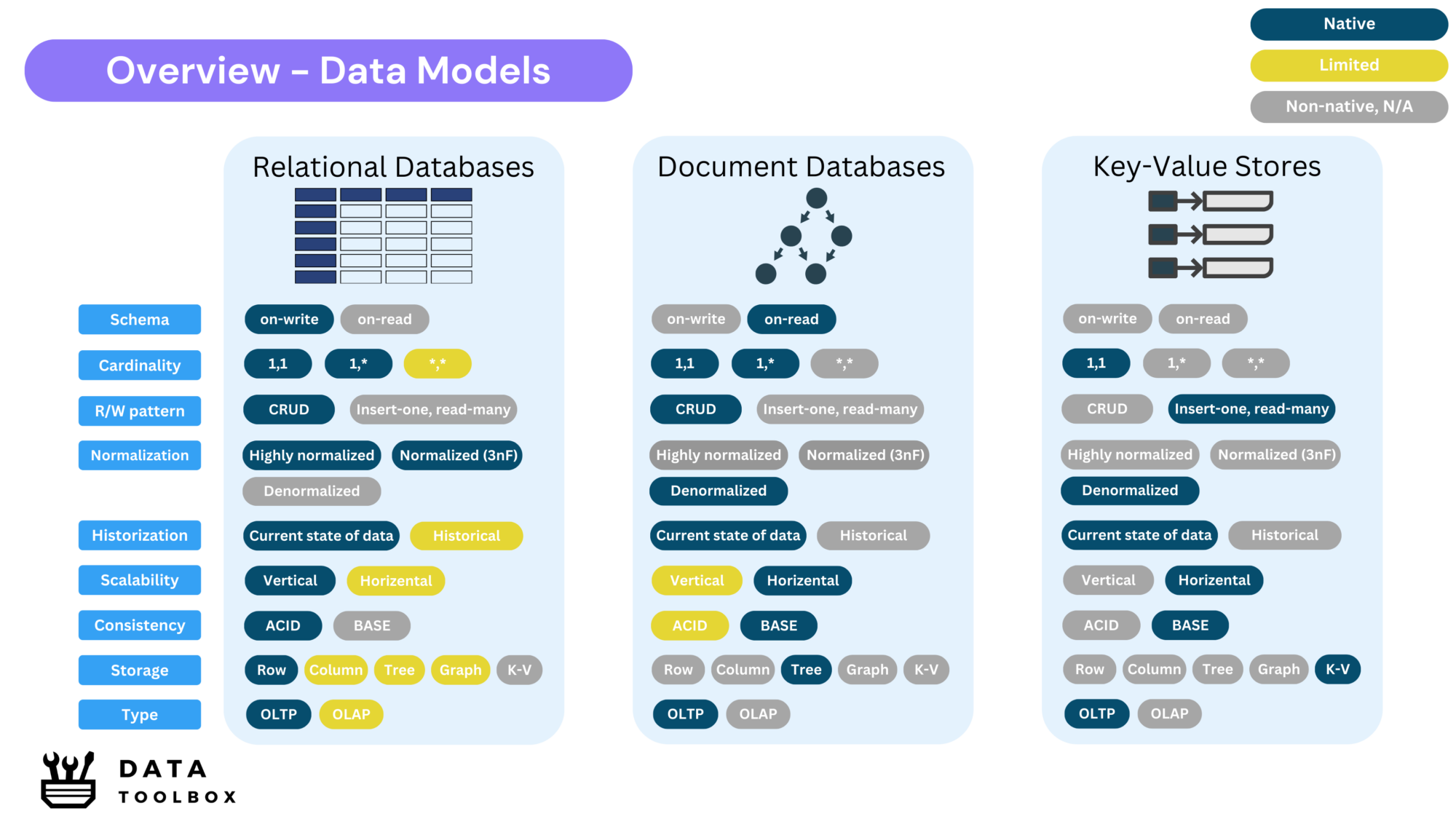
Relational Databases (RDBMS), or the structured workhorses
Relational databases have been the backbone of structured data storage since the early days of computing in the 1970s. Initially built for heavy business applications that demanded strong consistency, they remain widely used today, and have even evolved to incorporate some NoSQL-style features.
- Structure: Data is stored in structured tables with rows and columns.
- Schema enforcement: Schema-on-write, data must adhere to a predefined structure before insertion.
- Cardinality pattern: Supports all cardinality patterns. Other technologies can be more suitable for one-to-many (document) and many-to-many (graphs).
- Write behavior: Fully supports CRUD (Create, Read, Update, Delete) operations, with write patterns typically consisting of high-frequency and small-sized transactions.
- Consistency model: Fully ACID-compliant (Atomicity, Consistency, Isolation, Durability).
- Normalization: Typically highly normalized to reduce redundancy and ensure integrity.
- Historical data: Mainly optimized for storing the current state, allowing fast lookups and efficient index management. Historical data is typically offloaded to separate tables or analytical systems that use columnar storage for better performance.
- Scalability: Traditionally vertical scaling (adding more power to a single server); horizontal scaling is complex and requires sharding or replication strategies.
- Best suited for: OLTP systems like financial systems, ERP, inventory management, CRM or transactional applications.
- Modern evolution: Many RDBMS now support JSON storage, distributed architectures, and also graphs (e.g. SQL Graph) !
- Technologies: PostgreSQL, MySQL, Microsoft SQL Server, Oracle, SQLite, CockroachDB
Document Databases, or the flexible choices
Document databases emerged in the 2000s as part of the NoSQL (Not-only SQL) movement, offering a more flexible way to store semi-structured data and scale out more easily. These qualities have made them popular for modern web applications.
- Structure: Data is stored as JSON-like documents (often in BSON format).
- Schema enforcement: Schema-on-read, documents can have different structures without a predefined schema.
- Cardinality pattern: Optimized for one-to-many relationships (tree-like relationships).
- Write behavior: Supports CRUD pattern like RDBMS.
- Consistency model: BASE (eventually consistent) with some support ACID transactions within a single document. Not to use for finance or ERP systems, when strong ACID is needed!
- Normalization: Typically denormalized, related data is stored within documents rather than in separate tables.
- Historical data: Can store both current state and historical data within document revisions both focus on current state of the data.
- Scalability: Horizontally scalable, with built-in sharding for large distributed workloads.
- Best suited for: User profiles, catalogs, content management, logging, flexible data applications.
- Common pitfall: Schema flexibility can lead to inconsistencies over time, making queries unpredictable.
- Technologies: MongoDB, CouchDB, Amazon DocumentDB
Key-Value Stores, or the speed demons
One of the oldest data storage models, key-value databases have been adapted for modern high-performance applications. They are used particularly for caching and real-time processing.
- Structure: Simple key-value pairs with no predefined schema.
- Schema enforcement: No schema; data is stored exactly as provided.
- Cardinality pattern: Supports only one-to-one lookups (each key maps to a single value).
- Write behavior: Insert-once, read-many, optimized for high-speed lookups.
- Consistency model: BASE (eventual consistency), some offer strong consistency via replication.
- Normalization: No normalization, each key is independent.
- Historical data: Typically does not track history, focuses on the latest state, like the position of a player in a video game or session information.
- Scalability: Highly scalable horizontally, often used in distributed architectures.
- Best suited for: Caching, session storage, leaderboards, real-time analytics.
- Technologies: Redis, Memcached, DynamoDB
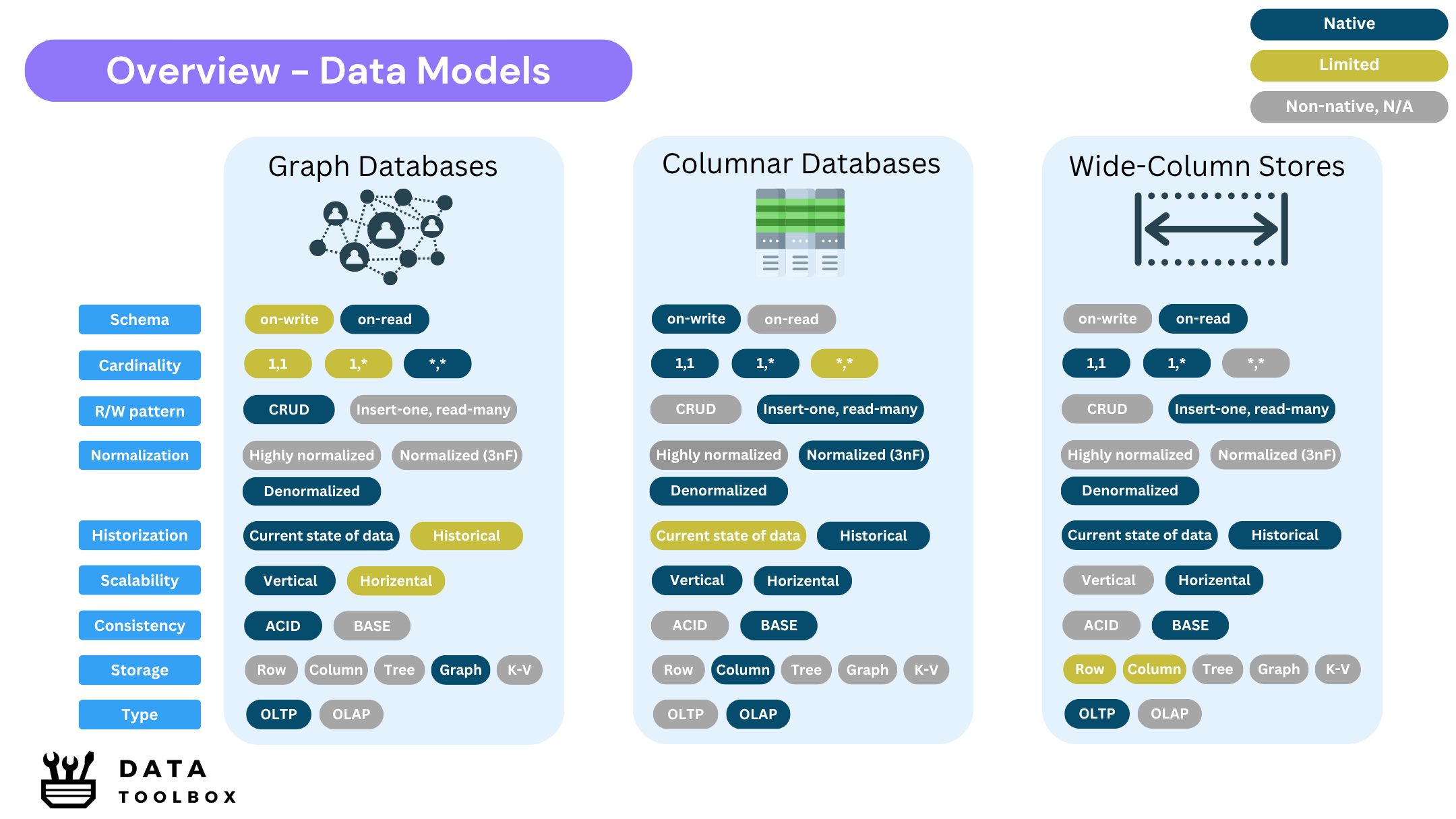
Graph Databases, or the relationship powerhouses
Graph databases were developed in the 2000s to handle data where relationships are as important as the data itself, making them ideal for social networks and recommendation engines.
- Structure: Data is represented as nodes (entities) and edges (relationships).
- Schema enforcement: Schema-on-read, relationships must be predefined but nodes can be flexible.
- Cardinality pattern: Optimized for many-to-many relationships.
- Write behavior: Supports CRUD, but specialized for graph traversal queries.
- Consistency model: ACID-compliant in most graph databases.
- Normalization: Typically denormalized within nodes, resembling embedded JSON-like structures for faster traversal.
- Historical data: Typically stores current state, but some support time-travel queries.
- Scalability: Difficult to scale horizontally, but distributed graph databases exist (e.g., JanusGraph).
- Best suited for: Social networks, fraud detection, recommendation engines, supply chain analysis.
- Examples: Neo4J, Amazon Neptune
Columnar Databases, or the analytical wizards
Columnar databases were born from the need to run heavy analytics without impacting transactional systems. They are developed to enhance analytical performance, particularly for large-scale reporting and business intelligence.
- Structure: Data is stored in structured tables with rows and columns, like in relational databases. However, under the hood, data is stored in a column format rather than by row, improving read performance (see heuristic here).
- Schema enforcement: Schema-on-write structured, predefined columns.
- Cardinality pattern: Best for one-to-many relationships, not designed for complex joins.
- Write behavior: Insert-once, read-many, optimized for large batch queries.
- Consistency model: BASE (eventual consistency), optimized for large-scale reads.
- Normalization: Denormalized to optimize analytical queries.
- Historical data: Designed for storing and analyzing historical data.
- Scalability: Highly scalable, supports MPP (Massively Parallel Processing).
- Best suited for: Data warehousing/lakehousing, BI analytics, operational analytics.
- Examples: BigQuery, Redshift, Snowflake, Teradata, Exadata
For info, Lakehouse platforms like Fabric and Databricks is considered as “columnar-ish.” While they don’t rely exclusively on columnar storage engines, they leverage columnar file formats such as Delta Lake or Parquet for efficient analytics.
Wide-Column Stores, or the scalable giants
Evolving from columnar and key-value models, wide-column stores are designed for high write throughput and massive distributed workloads. It’s like a cheap horizontal RDBMS that dropped ACID properties to scale horizontally!
- Structure: Hybrid row-column model, each row can contain a flexible set of column key-value pairs tailored to its own schema.
- Schema enforcement: Schema-on-read rows can vary in column structure.
- Write behavior: Insert-once, read-many, optimized for high write throughput.
- Consistency model: BASE (eventual consistency), with tunable consistency settings.
- Normalization: Typically denormalized for fast lookups (most don’t support joins !).
- Historical data: Supports both current state and historical data tracking.
- Scalability: Horizontally scalable, built for distributed workloads.
- Best suited for: IoT, time-series data, recommendation engines, high-throughput event storage.
- Examples: Cassandra, Google Bigtable, Apache HBase, ScyllaDB
Other specialized data technologies
Some databases are built for specialized workloads, optimized for specific data retrieval patterns. They complement general-purpose databases by enhancing search, analytics, and AI capabilities.
- Vector Databases (Pinecone, Weaviate, FAISS, pgVector) : Designed for AI-driven similarity search, storing data as high-dimensional vectors for semantic search, recommendations, and generative AI.
- Search Engines (Elasticsearch, Apache Solr) : Optimized for full-text search, ranking results using inverted indexes and relevance scoring. Ideal for e-commerce, log search, and application search.
- Time-Series Databases (InfluxDB, TimescaleDB) : Built for time-ordered data, enabling fast ingestion, retention policies, and time-based queries. Used in IoT, system monitoring, and financial analytics.
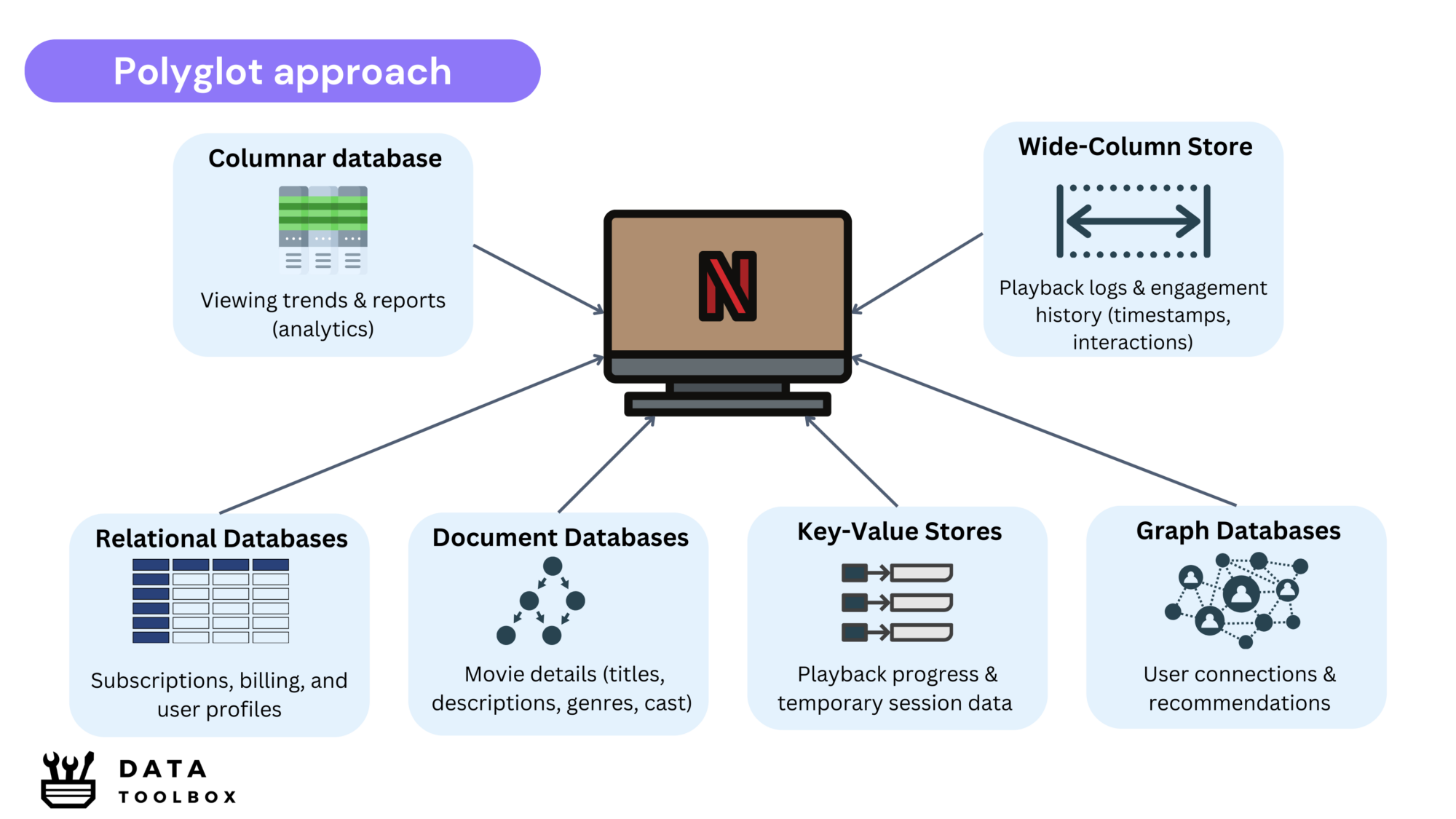
Bridging Theory to Reality
A single database type is rarely enough to meet all performance and scalability needs. Instead, we adopt a polyglot persistence approach, combining multiple databases, each optimized for a specific workload.
Key Takeaways
Don’t be Homer Simpson (Mmmh…) ! Choosing the right data model is like picking the right tool for the job, you wouldn’t use a screwdriver to hammer a nail ! Every database type has strengths and trade-offs, and modern systems mix and match to get the best of all worlds :
- 1️⃣ Pick the right tool: Databases are designed for specific workloads, so use them accordingly.
- 2️⃣ RDBMS still rules: The most widely used model, now bridging gaps with NoSQL through JSON support.
- 3️⃣ NoSQL isn’t one thing: Document, key-value, and graph databases serve vastly different purposes.
- 4️⃣ Scalability matters: RDBMS typically scale vertically, with some supporting horizontal scaling through additional effort. In contrast, NoSQL databases are designed for horizontal scalability, though often at the cost of consistency.
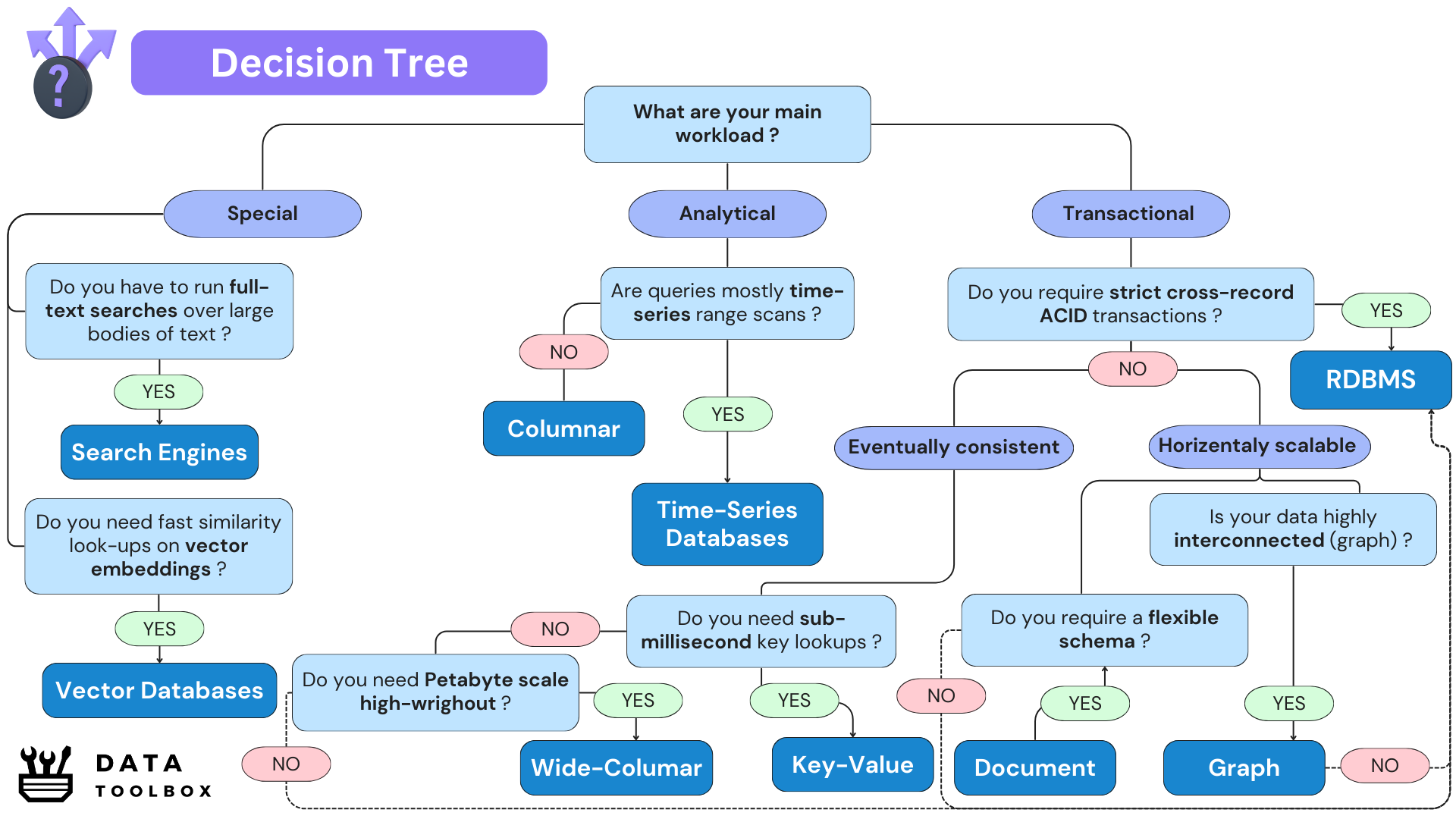
I have made for you a beautiful decision tree 💘 so you quickly have a clue about what to choose and why :
If you wish to expand your knowledge of database technologies, you can explore The Foundation of a Scalable Data Architecture : Data Storage.