

Introduction
Hello, all data lovers 👋 ! Today, I want to talk about a subject that is absolutely crucial for every organization. We all know that data architecture is a broad discipline encompassing data modeling, processing, governance, security, and storage.
However, I believe that among these, data storage serves as the backbone of how businesses manage, retrieve, and analyze data efficiently. A well-planned storage strategy enables seamless operations, enhances analytics, and supports effective decision-making !
Let’s dive into the foundational elements of data architecture, where ODS, MDM, and various data core components come together to shape efficient data management strategies.
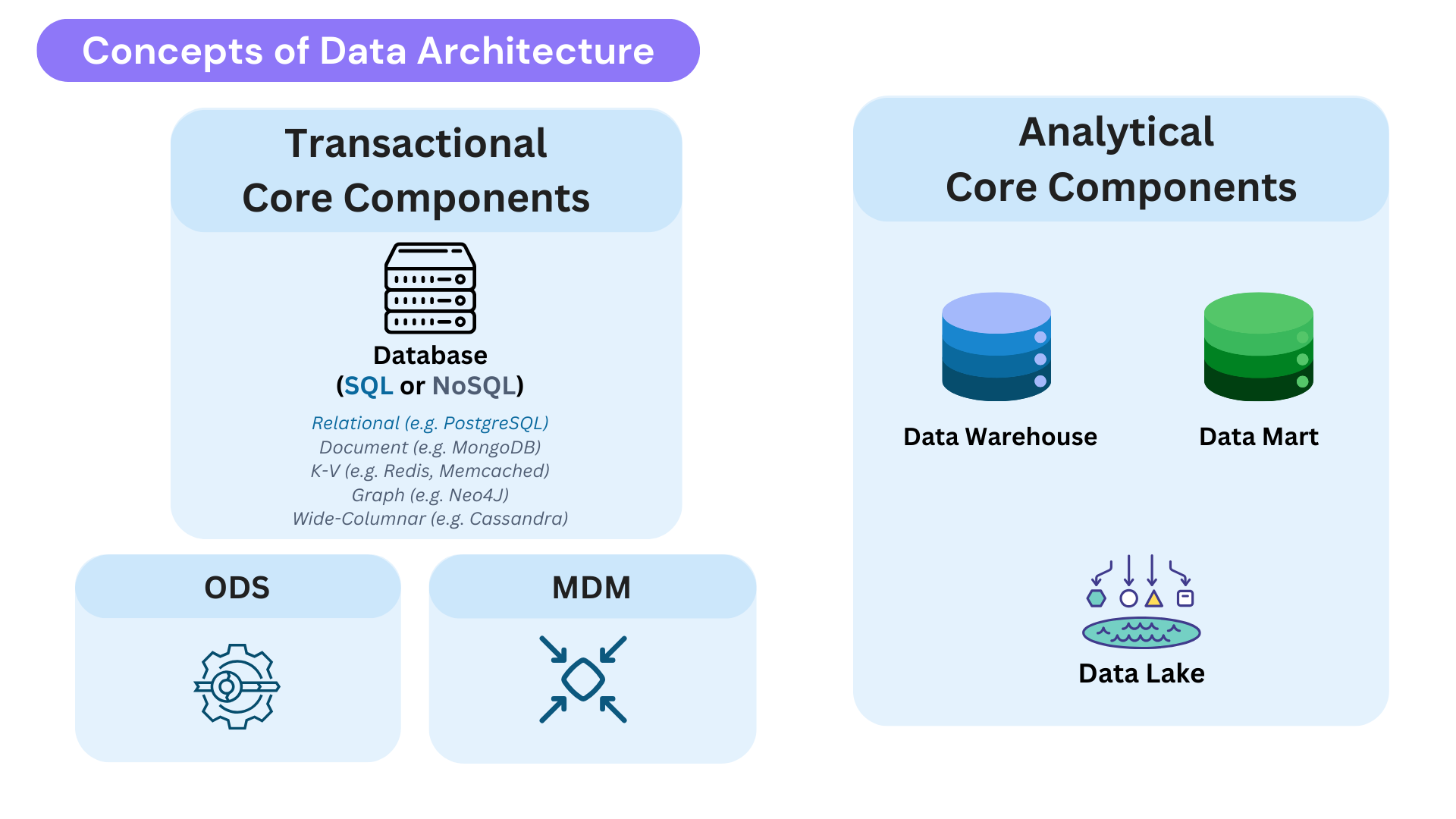
Core Components of Transactional Storage
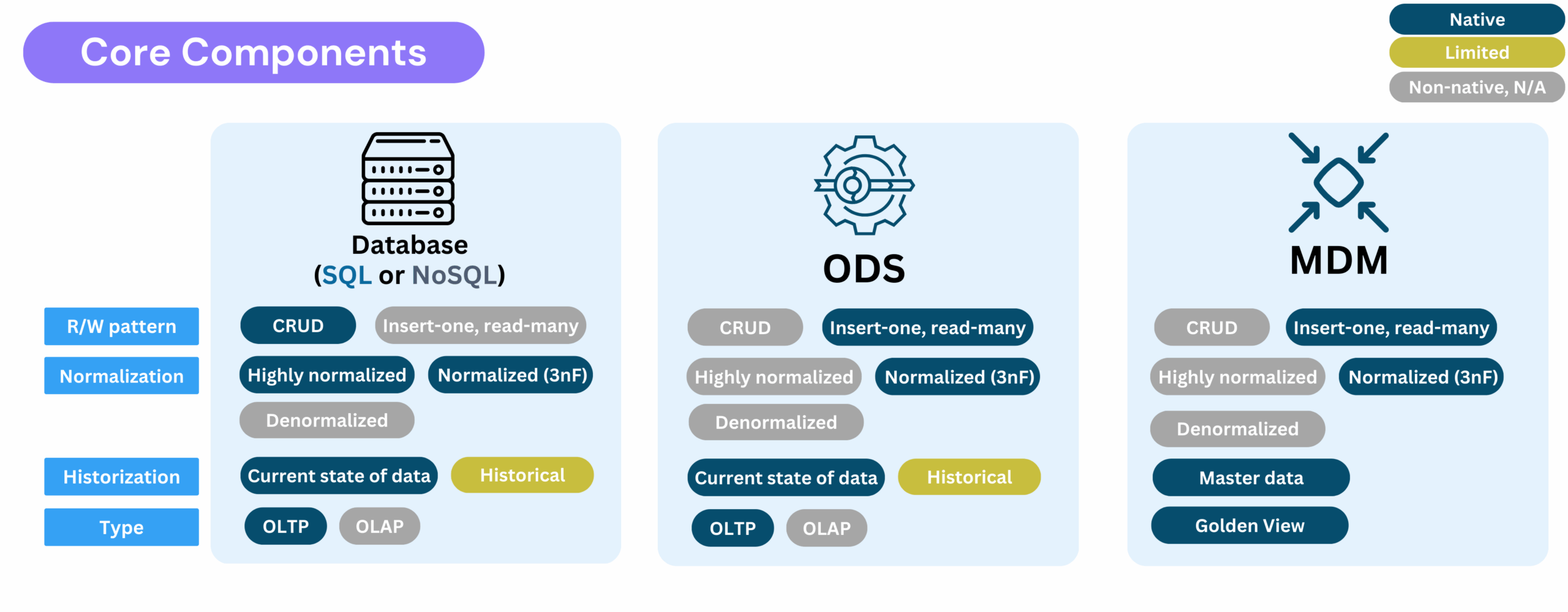
To put it rapidly, OLTP systems are designed for real-time, high-speed transactional workloads, ensuring data consistency and rapid access. They support business-critical applications like e-commerce platforms, CRMs, and ERPs by executing frequent CRUD operations (Create, Read, Update, Delete) efficiently.
OLTP systems typically store only the current state of data (not historical), and their schemas are often highly normalized to minimize redundancy and maintain data integrity during transactions.
In practice, organizations often operate multiple OLTP systems tailored to different use cases, ranging from relational databases (like PostgreSQL or Oracle) to NoSQL stores (such as document-based MongoDB or key-value Redis) to handle a variety of operational workloads.
Some terminology
- A transactional database (SQL) is an ACID-compliant system, typically relational, that ensures data consistency and reliability, making it ideal for critical systems like finance.
- An operational database (SQL + NoSQL) is a broader term for any database used to run daily business operations. These include relational databases, document-based, and all NoSQL stores.
You can read Analytical vs Transactional will be valuable to know the difference between OLTP and OLAP storage.
Side Horses
In modern data architectures, the spotlight often shines on high-profile data platforms, but it’s the side horses like ODS and MDM that work quietly behind the scenes to ensure consistency, integration, and operational harmony. Let’s uncover what they are and why they are important !
Operational Data Store (ODS)
Use Case: A customer visits an e-commerce website. We need to instantly check if a red shirt is in stock across multiple warehouses with different inventory systems. How do we ensure real-time availability?
The answer is an Operational Data Store (ODS): a consolidated, near-real-time repository that integrates operational data from multiple sources.
- Delivers a current snapshot of operations to support real-time business needs.
- Uses a less normalized structure than OLTP systems, optimized for fast queries and reporting.
- Offers an integrated, up-to-date view of data for operational reporting and applications.
- Can serves as an intermediary between OLTP and analytical systems, exposing a normalized current state that lands in bronze via CDC or snapshots, then is consolidated and historized in silver for downstream analytics.
- Heuristic: Conceptually similar to consolidating fact tables from various sources (e.g., sales, inventory, etc.) when same data doesn’t overlap between sources.
Master Data Management (MDM)
Use Case: An insurance company formed through mergers and acquisitions now has three business units: Health, Retirement, and Life Insurance. Historically, their operational systems (e-commerce, CRM, ERP) were never integrated. This leads to duplicate customer records, inconsistent marketing communications (sending 3 mails to the same consumers), and compliance risks (e.g. global opt-in/out). How do we unify these records into a single view?
This is where Master Data Management (MDM) comes in. MDM governs reference data across an organization to ensure consistency, accuracy, and compliance.
- Centralizes business-critical data (e.g., customers, products, suppliers).
- Ensures a Single Version of the Truth (SVOT) to support regulatory and operational requirements from multiple siloed sources. In real-life scenarios, this may arise due to mergers and acquisitions, siloed business units, or a lack of interoperability between systems.
- Feeds both OLTP (real-time operations) and OLAP (historical analysis) environments.
- Heuristic: Conceptually similar to consolidating dimension tables from various sources (e.g., product, customer data), when same data does overlap between sources.
👉 Another interesting point here is that MDM is not only a tool or a data repository, but also encompasses data governance and processes. It requires clear ownership, well-defined policies, and strong organizational alignment to ensure long-term success.
Summary
Core Components of Analytical Storage
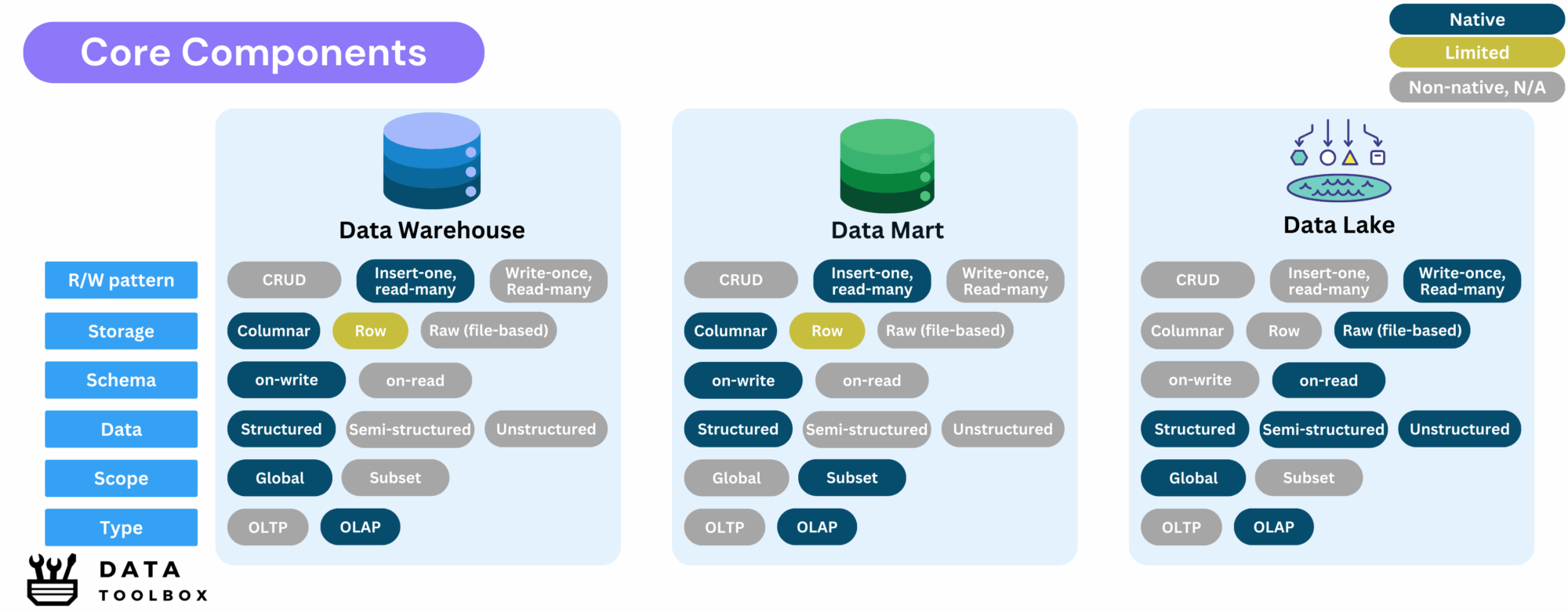
OLAP systems are designed for complex queries, reporting, and business intelligence applications. They facilitate large-scale historical data analysis, providing valuable insights for strategic decision-making.
⚠️ This chapter provides a brief explanation of each analytical storage system, if you want to have a deep overview, please read here Data architecture in real-life : Warehouse, Lake, Lakehouse, Fabric and Mesh.
Data Warehouse
A data warehouse (DWH) is a structured repository designed to store, process, and analyze historical and aggregated data. It is optimized for high-performance analytics, complex queries, and business intelligence (BI) applications.
- Relational data using columnar based storage, optimized for high-performance analytics.
- Global in scope, catering to organization-wide analytical needs.
- Designed to handle complex queries efficiently.
- Insert-once, read-many pattern to ensure data integrity.
- Primarily used by business analysts, data analysts, and data scientists to generate insights, develop dashboards, and conduct data science projects.
- Use case: A retail company consolidates years of sales data in a data warehouse to analyze seasonal trends and forecast demand.
- Technologies: Snowflake, Amazon Redshift, Google BigQuery.
Data Mart
A data mart is a subset of a data warehouse, tailored to serve a specific subject (like a dashboard), business units or departments, such as finance, marketing, or sales.
- Subset of a data warehouse, providing a smaller, more manageable dataset.
- Optimized for OLAP workloads within a specific domain.
- Use case: The finance department maintains a financial data mart to track revenue, expenses, and profitability, enabling focused reporting and budgeting.
Data Lake
A data lake is a scalable storage system designed to handle vast amounts of raw data in various formats, including structured, semi-structured, and unstructured data.
- File-based storage system supporting raw data ingestion.
- Schema-on-read architecture allows flexible data processing.
- Write-once, read-many model: modifying a file requires replacing the original.
- Mainly used by Data Scientist for big data processing, machine learning, and AI applications.
- Use case: A healthcare organization stores patient records, medical images, and IoT device data in a data lake, enabling advanced analytics and predictive modeling.
- Technologies:
- Storage: HDFS, AWS S3, Azure Data Lake, Google Cloud Storage
- Processing: Spark, Hive, Flink
- Formats: Parquet, ORC, Avro
Summary
Global overview
Here is a global overview (sorry if it’s a bit dense), about the real-life relationships between analytical and transactional systems in the real world!
Conclusion

I know this article was long, but I believe it was necessary to help you understand the differences between what we call the core concepts of data storage, what I like to call the side horses 🐎.
In the next article, we’ll explore how all these concepts come together to form data architecture paradigms such as the Traditional or Hybrid Data Warehousing, Data Fabric, Lakehouse, and more. You can read it here: Data architecture in real-life: Data Warehouse, Lakehouse, Fabric and Mesh.
Learning to distinguish between “shiny objects” and well-established concepts will be invaluable in navigating the evolving world of data architecture !