

Disclaimer
This article is part of a series, we highly recommend reading the following articles:
- Analytical vs Transactional: Why You Can’t Mix Oil and Water
- The Foundation of a Scalable Data Architecture: Data Modeling 101
These will provide the necessary context to fully grasp the concepts we discuss here.
Introduction
In our previous discussion, we explored what a data model is, its different layers, and how to transition from a high-level conceptual model to a physical model.
The physical model depends on the underlying database technology, as different systems handle storage, indexing, and optimization differently. However, before reaching that stage, we need a well-structured logical model, where normalization plays a key role in organizing data efficiently.
Is storing all data in a single large table more efficient than breaking it into multiple smaller and related tables? What are the trade-offs between performance, scalability, and maintainability in each approach?
How it works
Don’t Repeat Yourself !
Edgar F. Codd (the father of relational databases)
At its core, normalization follows the principle of Don’t Repeat Yourself (DRY). This ensures that each piece of data is stored only once, reducing redundancy and improving data integrity.
By structuring data into multiple related tables, normalization enhances consistency and simplifies data maintenance. However, this comes at the cost of increased complexity in query execution, as joins become necessary to retrieve related data.
Conversely, denormalization takes the opposite approach. Instead of distributing data across multiple related tables, it consolidates information into fewer or even a single wide table in extreme cases, minimizing the need for expensive joins and improving read performance.
📌 The higher the nF, the more structured and normalized the schema is.
The Normal Forms Explained

It took me a while to understand all the Normal Forms, so we’ll use a visually appealing canvas to help you grasp the concepts intuitively. The content will be presented as bullet points within collapsible toggles, allowing you to open them one by one and avoid information overload 🤯.
Passing from 0nF to 1nF
First Normal Form (1nF)
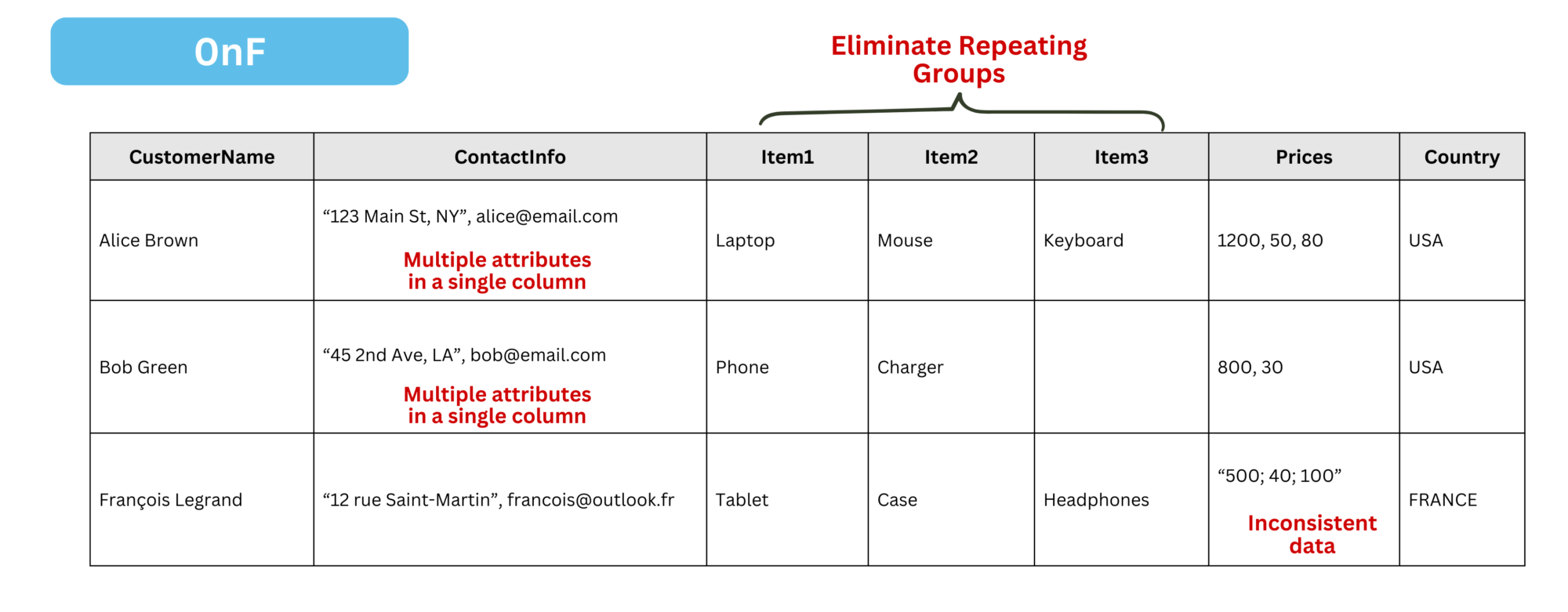
To convert a 0nF (unnormalized form) table into 1nF, we need to apply the following transformations:
- Ensure Atomicity: Each column must contain one indivisible value per cell. In 0nF,
ContactInfoandPricesstore multiple values (e.g.,"1200, 50, 80"). In 1nF, each item should be in a separate row. - Eliminate Multiple Attributes in One Column: In 0nF,
ContactInfomixes phone numbers and emails (e.g.,“123 Main St, NY”, alice@email.com). Split them intoAddressandContactEmail. - Eliminate Repeating Groups: Avoid multiple similar attributes in one table. Instead of
"Item1, Item2, Item3"and"Price1, Price2, Price3", store each item in a separate row with its price. - Ensure a Unique Identifier (Primary Key): Each table should have a primary key to uniquely identify each row.
- No Implicit Row Order: Row position should not convey meaning. If ranking is needed, use an explicit column like
PriorityLevelinstead of assuming the first row is more important than the second.
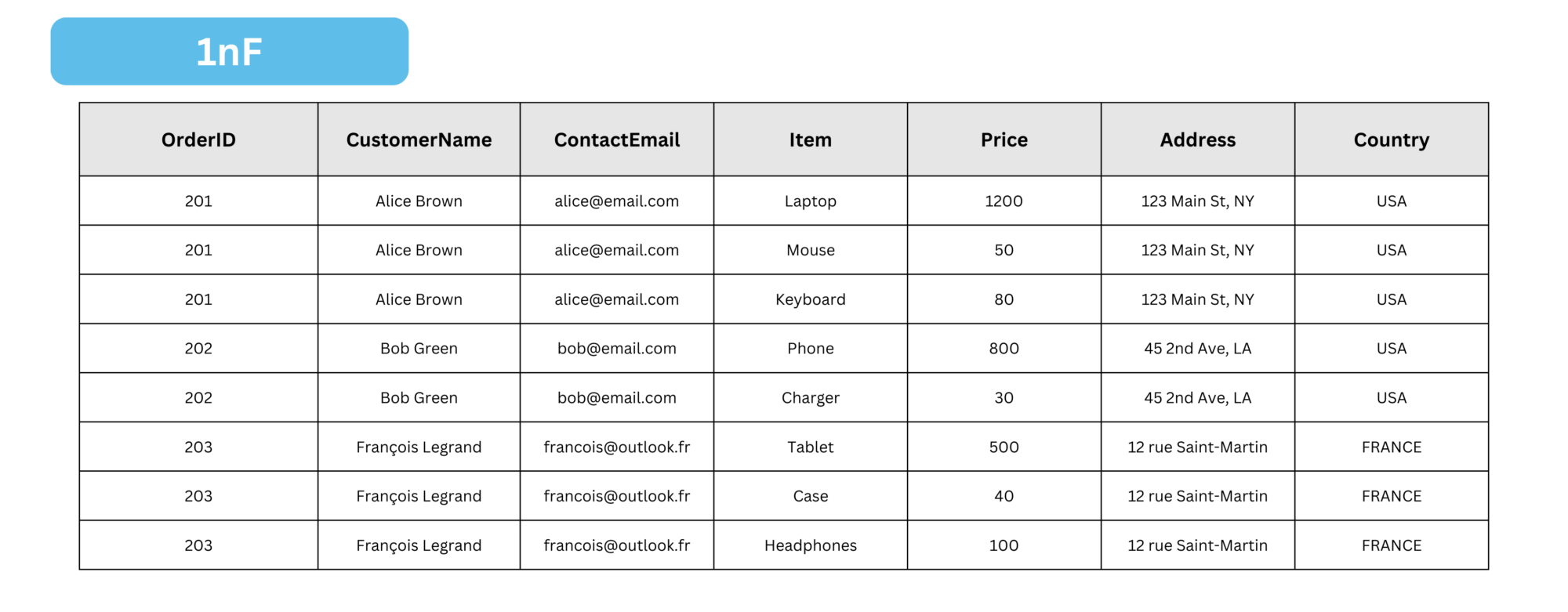
The result is :
Passing from 1nF to 2nF
Second Normal Form (2nF)
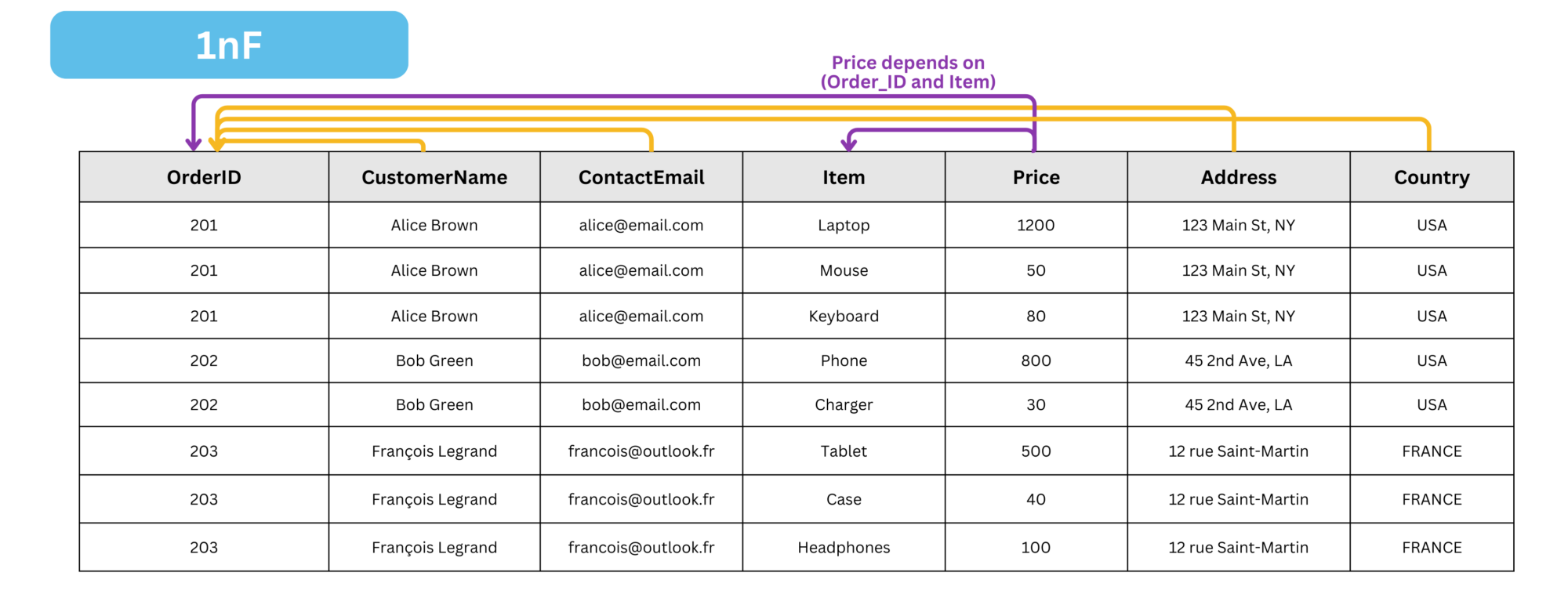
To convert a 1nF table into 2nF, we need to apply the following transformations:
- Ensure the table is in 1nF
- Eliminate Partial Dependencies :
- Ensure that all non-key attributes are fully functionally dependent on the entire primary key, not just a part of it.
- If a non-key attribute depends only on a part of a composite primary key, move it to a separate table along with the corresponding part of the key.
- In this case, some attributes (such as
CustomerName,ContactEmail,Address, andCountry) depend only on theOrder, so we place them in a separate table. On the other hand, attributes likePricedepend on both theOrderIDand theItem.
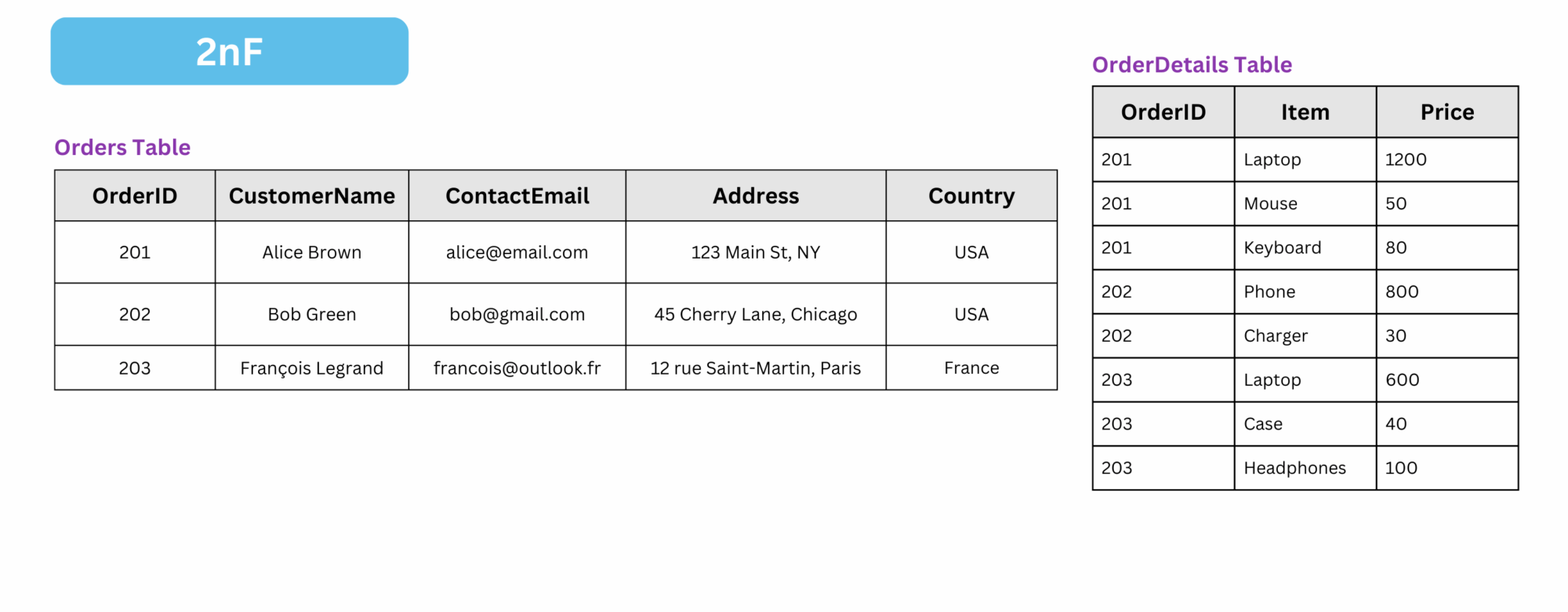
The result is:
Passing from 2nF to 3nF
Third Normal Form (3nF)
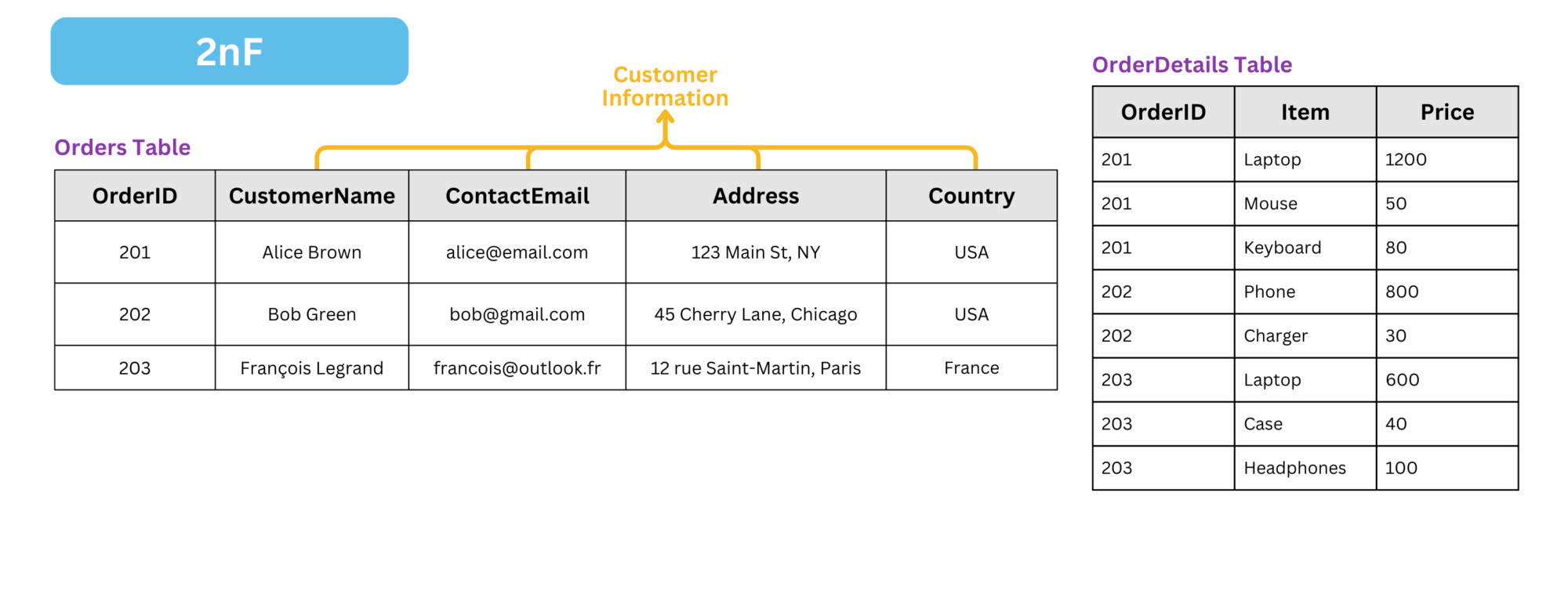
To convert a 2nF table into 3nF, we need to apply the following transformations:
- Ensure the table is in 2nF
- Remove transitive dependencies : A transitive dependency exists when a non-key attribute depends on another non-key attribute rather than directly on the primary key.
In this case:
- Transitive dependency:
CustomerName,ContactEmail,Address,Countryare linked toOrderID, but they actually depend onCustomerID(that we need to create), so they should be moved to a separateCustomertable.
The result is:
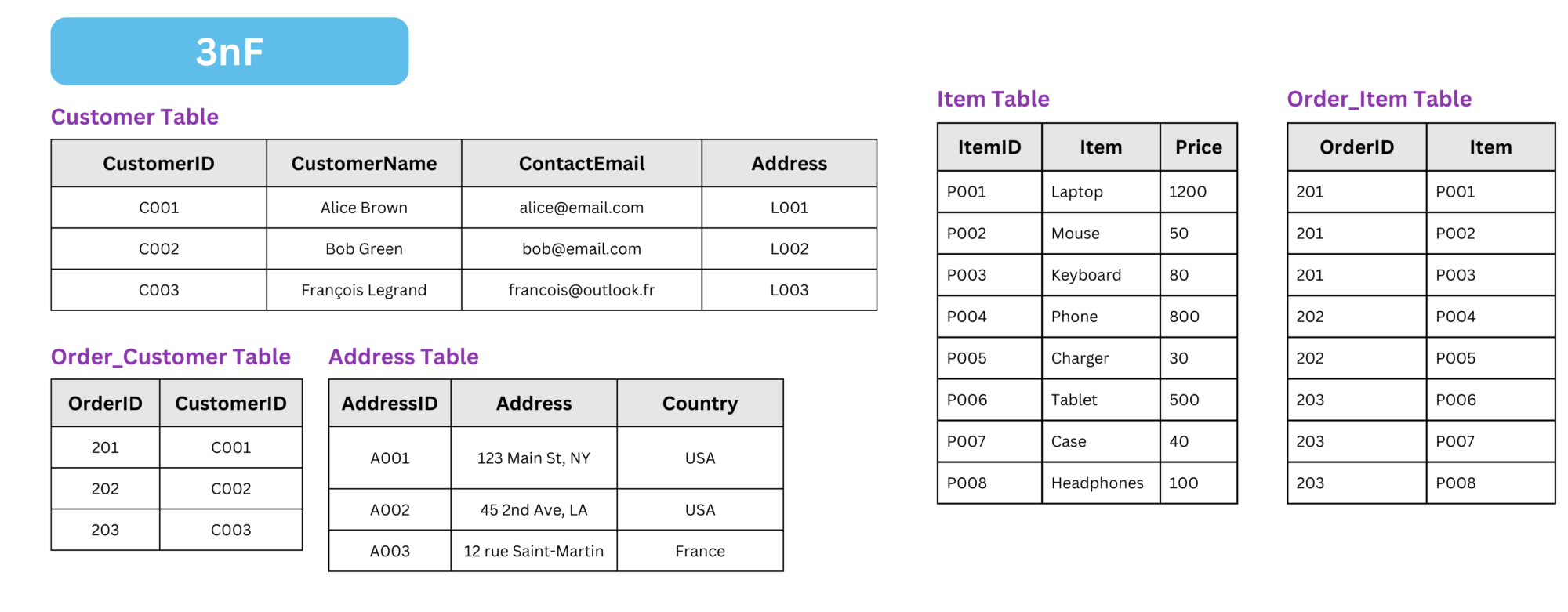
Passing from 3nF to BCNF (3.5NF)
Boyce–Codd normal form (3.5NF)
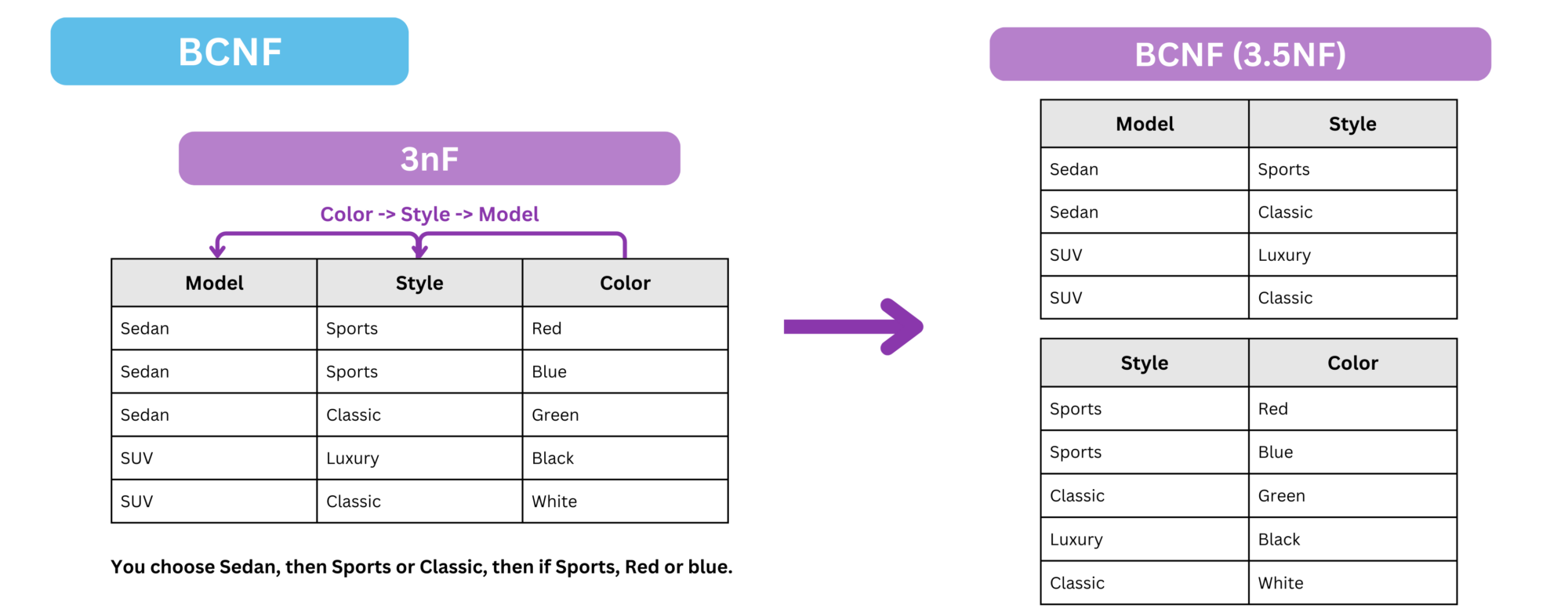
To convert a 3nF table into BCNF, we need to apply the following transformations:
- Identify functional dependencies where a non-superkey attribute determines another attribute.
- If a determinant (an attribute that functionally determines another) is not a superkey, decompose the table into smaller tables.
- Ensure that every determinant in the new tables is a superkey.
What is a superkey ?
A superkey is a set of attributes that can uniquely identify a row in a table. In other words, if you have a superkey, no two rows in the table can have the same values for those attributes. A superkey may contain additional attributes beyond what is necessary to uniquely identify a row, but it must always uniquely identify every row.In this case:
Coloris a determinant forStyle, butColoris not a superkey because it does not uniquely identify the row in the table. Similarly,Styleis a determinant forModel, but it is also not a superkey.- Therefore, we decompose the table into two smaller tables:
Model_Style, whereStyle→ModelandStyleis the superkey.Style_Color, whereColor→StyleandColoris the superkey.
- By decomposing into these two tables, we ensure that every determinant is a superkey, thus bringing the schema into BCNF.
Passing from BCNF to 4nF
Fourth Normal Form (4nF)
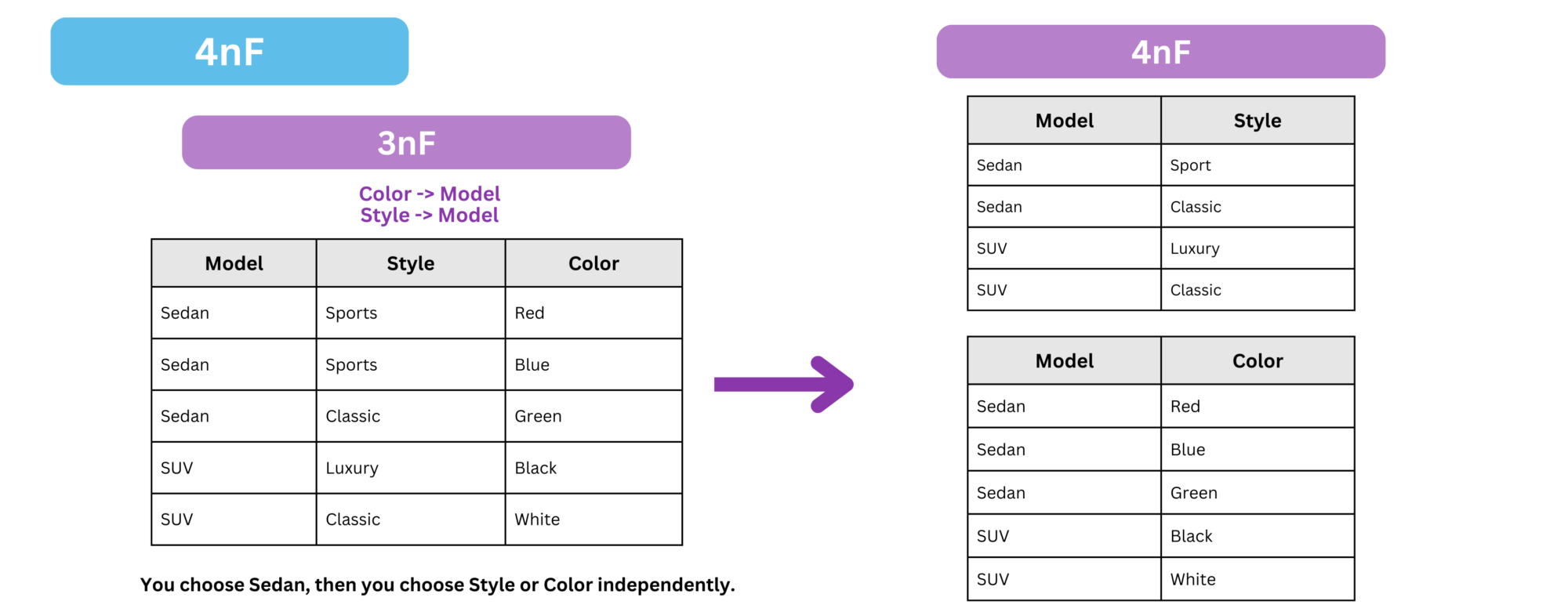
To convert a 3nF table into 4nF, we need to apply the following transformations:
- Identify Multi-Valued Dependencies (MVDs)
An MVD exists when one attribute determines multiple values of another, independently of other attributes. If a table has two or more independent MVDs, it is not in 4nF. - Check for 4nF Violation
A table violates 4nF if an MVD exists without being a functional dependency. - Decompose the Table
Split the table into separate relations, each containing only one independent MVD, ensuring no non-trivial MVDs except superkeys.
In this case:
The Identified Multi-Valued Dependencies:
Color→Model(Each model has multiple independent colors)Style→Model(Each model has multiple independent styles)
Since Style and Color are independent choices once Model is chosen, this table contains multi-valued dependencies that violate 4nF, we need to split the table into two separate relations.
Passing from 4nF to 5nF
Fifth Normal Form (5nF)
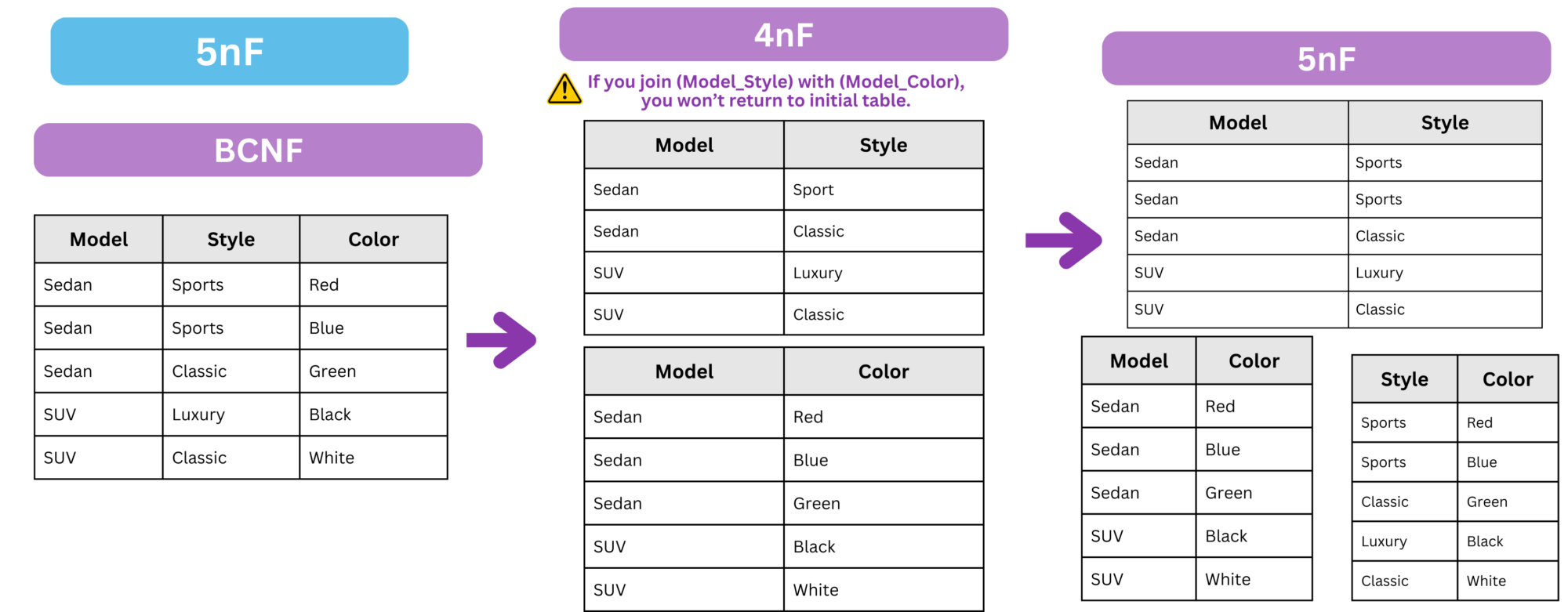
To convert a 4nF table into 5nF, we need to apply the following transformations:
- Identify Join Dependencies (JD) : A join dependency exists when a table can be decomposed into smaller tables without losing information and without introducing redundancy.
- Check if the Table Satisfies 5NF : This means that when we split the table into smaller tables, we should be able to reconstruct the original table by joining them without introducing spurious tuples (extra incorrect rows).
In this case: If we join Model_Style and Model_Color , we do not return to the original BCNF table. This indicates that a join dependency exists, requiring further decomposition into three separate tables.
This is similar to having a circular dependency between Model -> Style -> Color -> Model, each line is unique. It not about choosing a Model, then a Style or a Color; or a Color and a Style independently; here the Model, Style, Color is one choice (see them as one key). Thus, we now decompose the data into three relations to not lose any data : Model_Style, Model_Color , Style_Color.
Why BCNF is crucial for operational databases
Let’s try to do CRUD pattern on an 1nF table
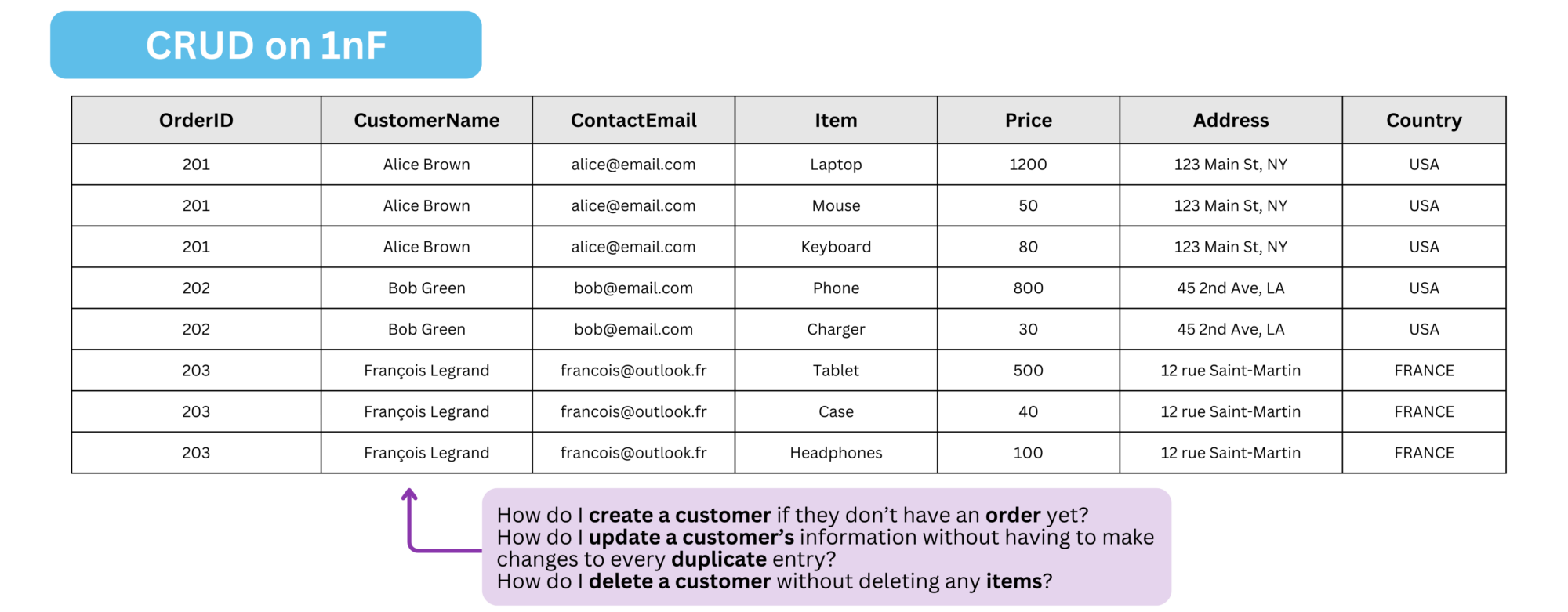
- Insertion Anomaly – You can’t create a new customer record unless you have an
OrderID. - Update Anomaly – Changing a customer’s details (email, address, etc.) has to be done in every row for every item they bought, risking inconsistencies.
- Deletion Anomaly – Deleting the last item of an order also removes the only copy of the customer’s data, wiping them out entirely.
This is why, achieving at least BCNF is essential for operational databases :
- Data Integrity: Ensures consistency and prevents anomalies.
- Storage Efficiency: Reduces redundant data.
- Index Performance: Optimized indexes speed up queries.
- Avoiding Anomalies: Prevents insertion, update, and deletion anomalies.
📌 Small tip: In OLTP systems, slight denormalization can improve performance. For example, if you have orders (order overview) and order_details (items per order), you can store pre-aggregated values like total_amount or item_count directly in the orders table. This avoids repeated joins and aggregations during reads. While it adds some redundancy, the trade-off is often worth it for speed.
⚜️ Others tips for BCNF modeling
1️⃣ Modeling multiple object types
– Use a single table with a type column when objects share a similar structure (e.g., components with type = 'sensor' | 'camera').
– Use separate tables when objects have different attributes or behaviors (e.g., sensor, camera, router).
→ Unified model = easier reporting; split model = better integrity and clearer business semantics.
2️⃣ Handling semi-structured attributes
– Use a key-value table like technical_data(entity_id, key, value) when fields vary or evolve frequently.
– Use a JSON column when your RDBMS supports efficient querying and the data is less critical or rarely filtered.
→ Use key-value when attributes are queried individually; JSON when you want schema flexibility.
3️⃣ When to promote an attribute to its own table
Promote the attribute when:
– It has high cardinality and is repeated often (e.g., country, currency).
– It is shared across multiple entities (e.g., users, companies, addresses).
– You need to apply global updates (e.g., renaming a country).
– It represents a separate business concept (e.g., address with its own logic or validation).
– You need historical tracking of changes (e.g., previous addresses).
Keep it as a column when:
– The attribute has low cardinality (e.g., "active", "inactive").
– It’s stable over time and not used across multiple entities.
→ Don’t over-normalize when there’s no practical benefit.
4️⃣ Keep reference tables lean
– Use a minimal structure for static values: id, name, and optionally code.
– Example: COUNTRY(id, name, code)
– Add metadata fields (e.g., created_at, is_active) only if the data is managed over time or modified by users.
→ Keep it lean unless there’s a clear business need for extra fields.
5️⃣ History tracking in OLTP systems
– Prefer append-only audit tables (e.g., user_audit) for recording changes.
– Use soft deletes or validity periods only when needed for compliance or business logic.
– See here for more details about history tracking.
→ OLTP is about current state; only model history when there’s a real need.
6️⃣ Avoid wide tables
– If a table has too many columns (especially optional ones), split it using a 1:1 *_details table (e.g., user and user_details).
– This improves performance, avoids NULLs, and clarifies structure.
→ Wide tables often indicate mixed concerns in the schema.
And in OLAP ?
Unlike transactional databases, data warehouses (or equivalent) don’t follow a CRUD pattern but store data for historical analysis (remember OLTP vs OLAP), making strict integrity constraints less important. Denormalized models are favored for analytics as they reduce joins and enhance read performance. Common OLAP modeling techniques include:
- Dimensional Modeling (Star, Snowflake, Galaxy schemas): Used for BI reporting, organizes data into facts and dimensions.
- Data Vault Modeling: Balances normalization and denormalization, ensuring auditability and historical tracking.
- Wide Table Schema: Stores all relevant data in a single table, minimizing query complexity.
You can learn more about OLAP modeling techniques here: Data Modeling: Star, Snowflake, Galaxy, Data Vault, Wide-Table.
Conclusion
Key, Superkey, Composite Key… This article was a hell to write 🧨! Normalization is defined mathematically, making it a real headache to explain simply with diagrams and examples.
If you want to dive deeper, take the time to re-read and really understand what each normalization level means. But don’t stress too much! In practice, no one’s rushing to normalize everything to 5nF or pulling out formal math to define a superkey. The real objective is simply to understand enough to design a data model that fits your needs, whether it’s for an operational system or an analytical one ⚓️.
Your data changes but how you model that change can make or break your system. Don’t guess. Read Masterclass Data Modeling: Data Mutability and Its Implications.